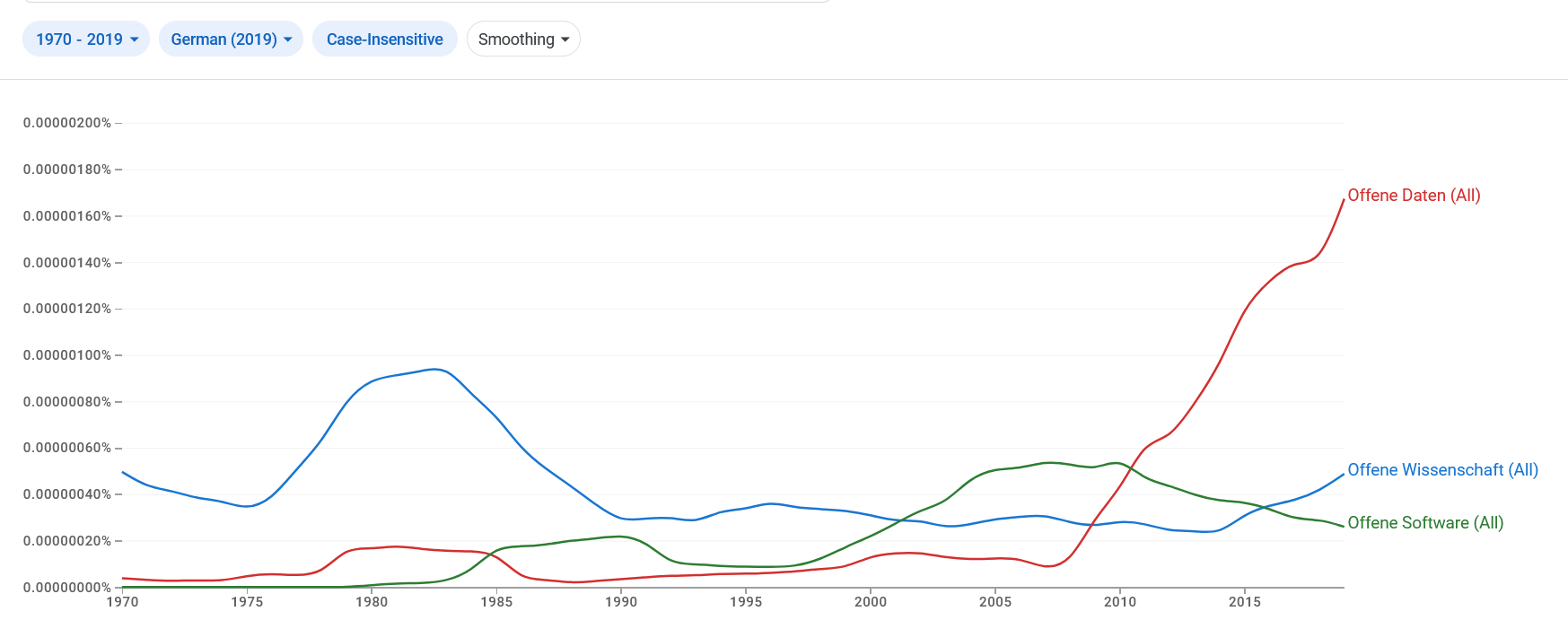
 Die Häufigkeit der Begriffe "Offene Wissenschaft", "Offene Daten" und "Offene Software" im Google Book Korpus für das Deutsche (https://books.google.com/ngrams/)
Die Häufigkeit der Begriffe "Offene Wissenschaft", "Offene Daten" und "Offene Software" im Google Book Korpus für das Deutsche (https://books.google.com/ngrams/) Am 4. Juli 2025 habe ich einen Vortrag beim 1st Workshop on Replication in the Language Sciences (WoReLa 1) an der Goethe-Universität Frankfurt gehalten. In diesem Vortrag hat unser Team gezeigt, wie man Daten aus Bildungsprojekten für weitere Forschungsprojekte öffentlich bereitstellen und dabei die Anonymität der Beteiligten wahren kann. Die Basis dafür war unser Projekt „Sprachkompetenzen neu zugewanderter Schüler*innen im Regelunterricht“ (SpraNZiR). Außerdem gibt es im heutigen Blogbeitrag natürlich – wie immer auf dem Sprache-Spiel-Natur.de-Blog – auch einen persönlichen Sprachspinat-Tipp zur Verbindung von Sprachbildung, Naturbildung und Bildung für nachhaltige Entwicklung (BNE). Diesmal geht es um Datenschutz als Thema für sprachsensible Bildung für nachhaltige Entwicklung im Schulgarten.
On July 4, 2025, I gave a presentation at the 1st Workshop on Replication in the Language Sciences (WoReLa 1) at Goethe University Frankfurt. In this presentation, our team demonstrated how data from educational projects can be made publicly available for further research while safeguarding the anonymity of the participants. The basis for our presentation was our project „Language Skills of Newly Arrived Students in Mainstream Education“ (SpraNZiR).
Inhalt/Content
- Workshop
- Präsentation/Presentation
- Informationen zu Open Science und zum SpraNZiR-Projekt
- Mein persönlicher Sprachspinat-Tipp

Why Open Science? (Gaelen Pinnock, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons; https://commons.wikimedia.org/wiki/File:Why-Open-Science.png)
Workshop
1st Workshop on Replication in the Language Sciences (WoReLa 1); Goethe-Universität Frankfurt
Workshop Announcement
The goal of the workshop is to build awareness of the replication crisis in linguistics and recommend specific interventions to improve it. Submissions will not just make it clear that there is a replication crisis, but also the factors associated with replicability and the greater consequences of low replication rates.
Workshop-Ankündigung
Ziel des Workshops ist es, das Bewusstsein für die Replikationskrise in der Linguistik zu schärfen und konkrete Verbesserungmaßnahmen vorzuschlagen. Die Beiträge sollen nicht nur aufzeigen, dass eine Replikationskrise besteht, sondern auch die Faktoren beleuchten, die mit der Replizierbarkeit zusammenhängen, sowie die weiterreichenden Konsequenzen niedriger Replikationsraten darlegen.
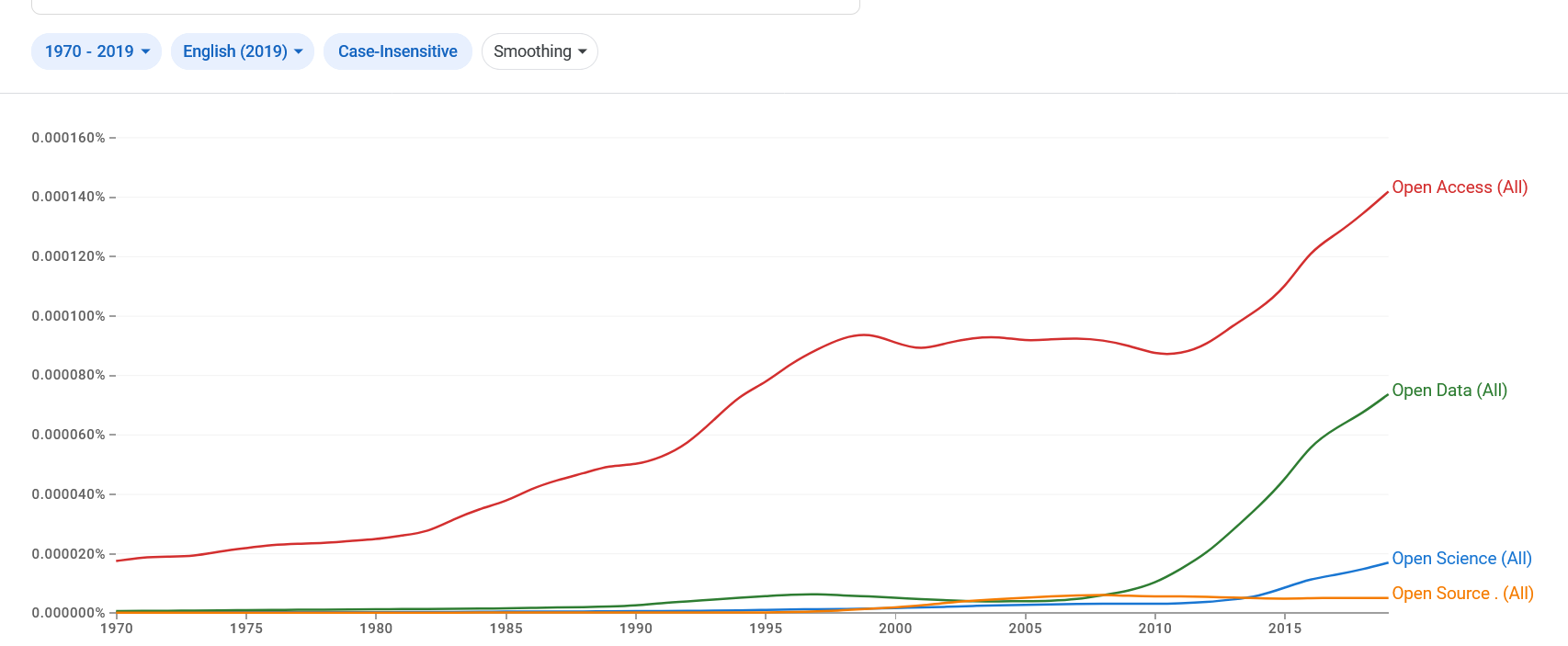
Die Häufigkeit der Begriffe „Open Science“, „Open Access“, „Open Data“ und „Open Source“ im Google Book Korpus für das Englische (https://books.google.com/ngrams/)
Programme
8:30 – 9:00 Welcome
9:00 – 10:00 Keynote talk 1 – Angela de Bruin:The importance of both direct and conceptual replication studies when studying language users from different language backgrounds
10:00 – 10:30 Coffee break
10:30 – 11:00 Ditch the lab and embrace the web: Small sample sizes lead to irreplicable results in Psycholinguistics (R. L. Beraldo)
11:00 – 11:30 Mapping links within the network of English Objoid Constructions: A replication study using T-Maze (T. Bouso, M. Hundt & L. Van Driessche)
11:30 – 13:00 Lunch break
13:00 – 13:30 Living meta-analyses in Language Sciences (P. Gomez, M. Perea, B. Angele, M. Vasilev & D. Allbritton)
13:30 – 14:00 How a paradigm and an erratic effect produced a fruitful but unreliable body of literature on grammatical gender processing (A. R. Sá Leite, K. Luna, M. Comesaña & I. Fraga)
14:00 – 14:30 Coffee break
14:30 – 15:00 Grammatical gender and beyond: Uncovering differences across women and men on the interplay between grammatical and emotional processing (L. Vieitez Portas, I. Padrón Rodríguez & I. Fraga Carou.)
15:00 – 15:30 LexOPS: A Reproducible Solution to Stimuli Selection (J. Taylor)
15:30 – 16:00 Low sampling rate is not an obstacle to making reading research more accessible (B. Angele, Z. Gunes Ozkan, M. Serrano-Carot & J. Andoni Duñabeitia)
16:00 – 16:30 Coffee break
16:30 – 17:30 Keynote talk 2 – Timo Roettger: Against replication
18:30 – 20:30 – Social event at TapHouse Frankfurt (Mendelssohnstraße 51, 60325 Frankfurt am Main)
Day 2: Friday, July 4th
9:00 – 10:00 Keynote talk 3 – Anne Beatty-Martínez: Research on Bilingualism as Discovery Science
10:00 – 11:00 Coffee break and poster session
11:00 – 11:30 “Well, I think it’s an ongoing struggle in a way”: A qualitative analysis of linguists’ understanding of and attitudes towards replication and open science (E. Le Foll)
11:30 – 12:00 Anonymity as a Challenge for Replicability and Reusability in Open Data: Insights from the German Project „Language Skills of Newly Arrived Students in Mainstream Education“ (S. Eisenbeiß, L. Twente, T. Barberio & N. Marx)
12:00 – 13:30 Lunch break
13:30 – 14:00 How replicable are bilingual interactive processing effects? A pre-registered close replication and extension of Dijkstra et al. (1999) (J. Witteman, L. Pablos-Robles, K. Karaseva & J. Wang)
14:00 – 14:30 Challenges of Replication and Restoration of Classic Language Studies (M. Dorin)
14:30 – 15:00 Coffee break
15:00 – 16:00 Keynote talk 4 – Bodo Winter: The Generalizability Crisis in Linguistics: Rethinking Statistical Traditions
20:00 Conference Dinner at Restaurant Lilium (Leipziger Str. 4, 60487 Frankfurt am Main)
List of posters:
Kyle Parrish, Nazanin Darvishi Rokni, Larissa Goncalves Miranda, Selma Inam & Pirthipal Zschernack. A systematic review and analysis of repeated measures designs in Language Learning
Elen Le Foll. Teaching Open Science to Language and Linguistics Students
Timo Roettger. ManyLanguages – Toward Big Team Language Sciences
John Cristian Borges Gamboa, Shaiban Alshaibani, Christopher Allison, Leigh Fernandez and Shanley Allen. Do people predict faster when they are many? Counter-intuitive Divergence Point Analysis results
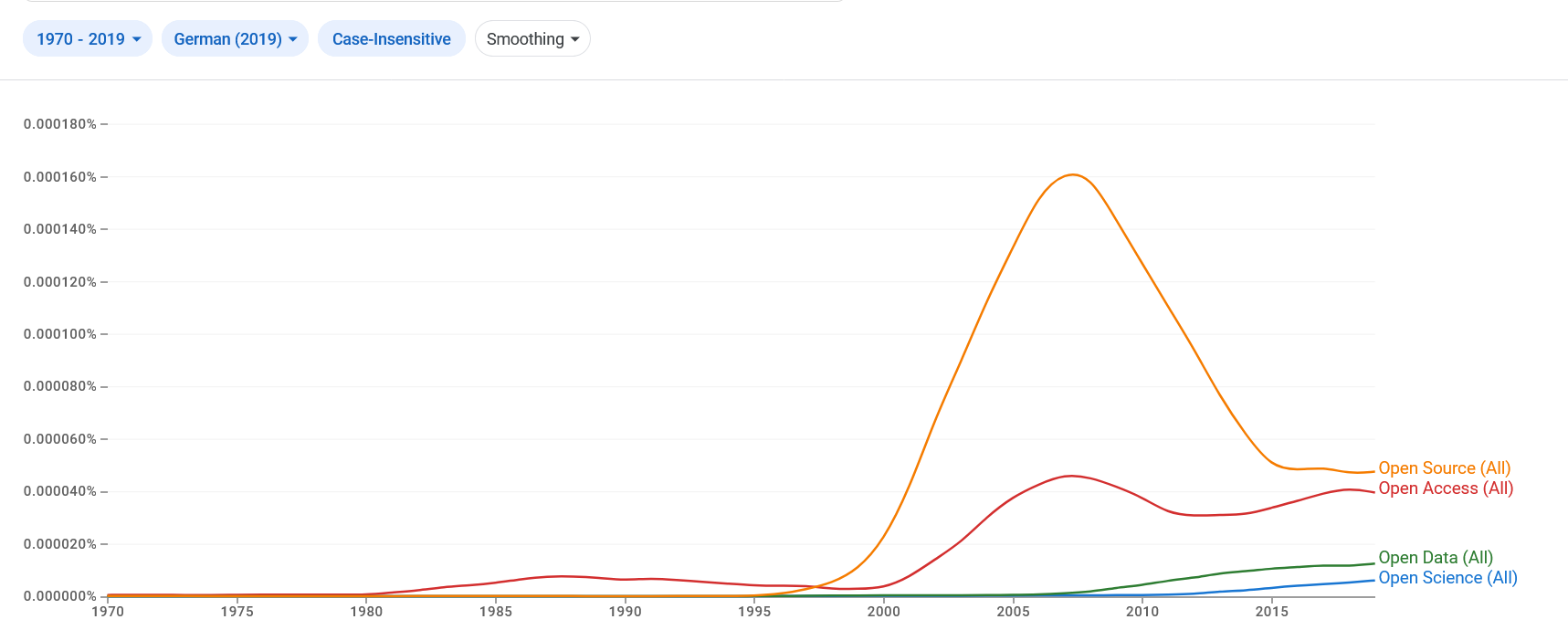
Die Häufigkeit der Begriffe „Open Science“, „Open Access“, „Open Data“ und „Open Source“ im Google Book Korpus für das Deutsche (https://books.google.com/ngrams/)
Präsentation/Presentation
Titel
Anonymity as a Challenge for Replicability and Reusability in Open Data: Insights from the German Project „Language Skills of Newly Arrived Students in Mainstream Education
Authors
- Sonja Eisenbeiß (Universität zu Köln),
- Leonie Twente (Universität zu Köln),
- Teresa Barberio (Universität Münster),
- Nicole Marx (Universität zu Köln),
Abstract (English)
Sharing research data on language development, including detailed information on individual characteristics of participants, enhances the potential for both secondary data analyses and replication studies. However, the more personal details included, the greater the risk of deanonymization of individual participants increases, requiring researchers to think about how to increase reusability and replicability, while maximizing protection against deanonymization. Drawing on our project „Language Skills of Newly Arrived Students in Mainstream Education“ as an example, our presentation explores decisions, practices, and challenges related to Open Science Practices when and data from vulnerable and diverse populations.
Since 2015, the increase in school-aged migrants to Germany has fueled a national interest in their language skills and educational outcomes. Despite this, there are very few comprehensive datasets available for research in this area. Our project addressed this gap by making our data available to researchers through the Research Data Centre at the IQB (https://www.iqb.hu-berlin.de/fdz), adhering to data and documentation quality standards for quantitative research. However, the population we studied presented us with challenges for data sharing: The children were vulnerable due to their age and often precarious residence status, many of them being refugees. In addition, the sample was highly diverse in terms of migration biographies, language backgrounds, and educational experiences. This diversity increases the risk of identifying individuals based on a combination of variables like age, gender, languages spoken, and country of origin, transit, or previous residence.
In this presentation, we detail the steps we took during different stages of the research process to maximize data reusability, reproducibility, and replicability while minimizing the risk of deanonymization. For instance, we discuss aggregating data and selectively removing variables that are less critical for other research projects but could potentially lead to the identification of participants. We will also discuss how we managed the preparation and documentation of our data set through (i) the development of Standard Operating Procedures (SOPs) for data entry, annotation, and documentation and (ii) standardization workshops for all members of the multiple sub-projects. Our goal is to provide insights into how to balance the competing demands of Open Science on the one hand and anonymity for vulnerable and diverse populations on the other hand.
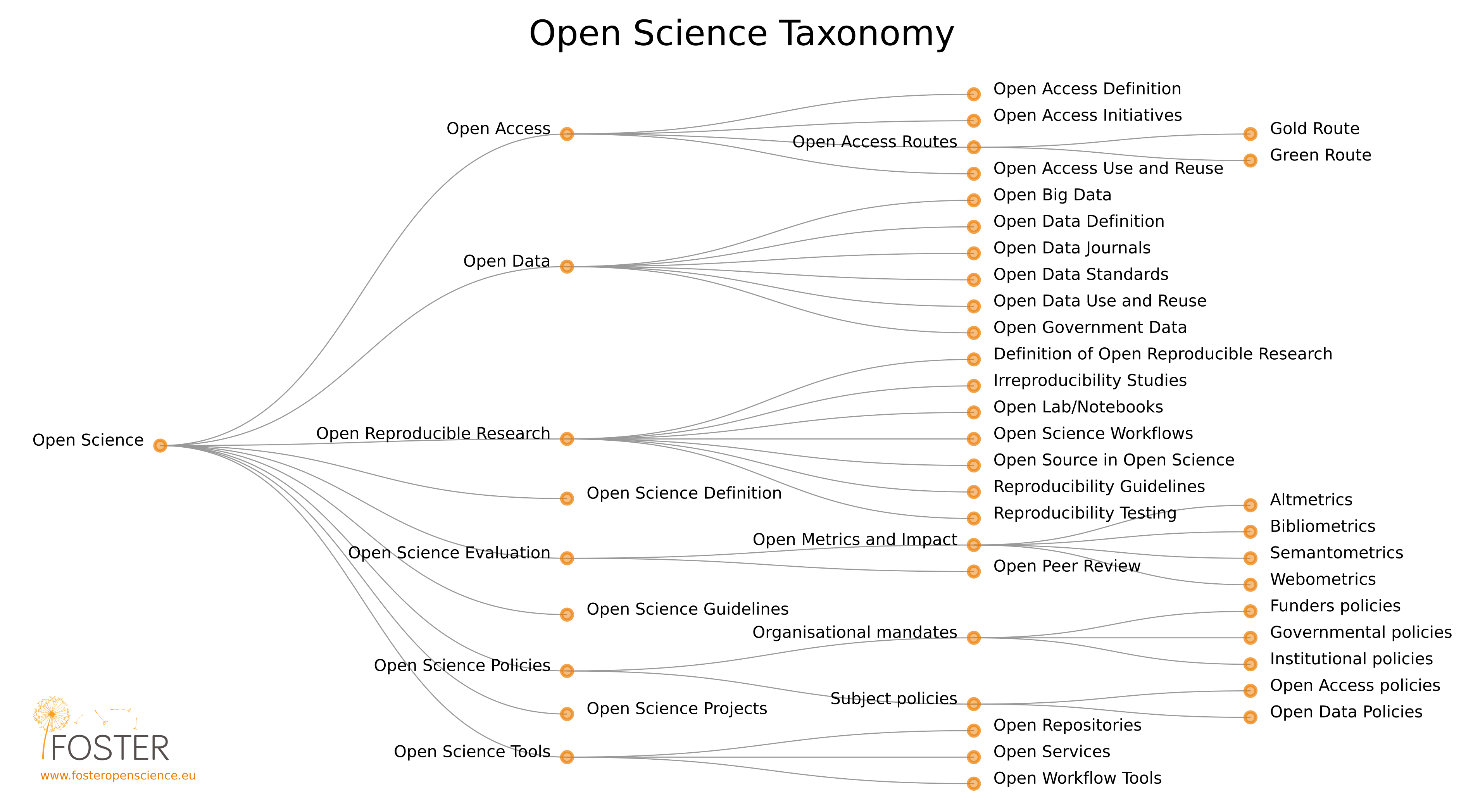
Die Open Science Taxonomy des Foster-Projekts (s. „Fostering Open Science to Research Using a Taxonomy and an eLearning Portal“ )
Abstract (Deutsch)
Die Weitergabe von Forschungsdaten zur Sprachentwicklung – einschließlich detaillierter Informationen zu individuellen Merkmalen der Teilnehmenden – erhöht das Potenzial sowohl für Sekundäranalysen als auch für Replikationsstudien. Je mehr personenbezogene Angaben jedoch enthalten sind, desto größer wird das Risiko der Deanonymisierung einzelner Personen. Forschende stehen daher vor der Herausforderung, Wiederverwendbarkeit und Replizierbarkeit der Daten zu fördern und gleichzeitig einen möglichst hohen Schutz vor Deanonymisierung zu gewährleisten.
Am Beispiel unseres Projekts „Sprachkompetenzen neu zugewanderter Schüler*innen im Regelunterricht“ beleuchten wir in unserem Beitrag Entscheidungen, Praktiken und Herausforderungen im Umgang mit Open-Science-Praktiken bei der Arbeit mit Daten vulnerabler und heterogener Populationen.
Seit 2015 hat der Anstieg schulpflichtiger Migrant*innen in Deutschland zu einem verstärkten öffentlichen und wissenschaftlichen Interesse an deren Sprachkompetenzen und Bildungserfolg geführt. Dennoch stehen bislang nur wenige umfassende Datensätze für die Forschung zur Verfügung. Unser Projekt hat diese Lücke adressiert, indem es Daten über das Forschungsdatenzentrum des IQB (https://www.iqb.hu-berlin.de/fdz) der wissenschaftlichen Community zur Verfügung stellt – unter Einhaltung gängiger Qualitätsstandards für quantitative Forschung und Dokumentation. Die untersuchte Population stellte uns jedoch vor spezifische Herausforderungen in Bezug auf die Datenfreigabe: Die Kinder waren aufgrund ihres Alters und häufig prekären Aufenthaltsstatus besonders schutzbedürftig, viele von ihnen geflüchtet. Zudem war die Stichprobe durch eine hohe Heterogenität hinsichtlich Migrationsbiografien, Sprachhintergründen und Bildungserfahrungen gekennzeichnet. Diese Vielfalt erhöht das Risiko, Einzelpersonen über eine Kombination von Merkmalen wie Alter, Geschlecht, gesprochene Sprachen sowie Herkunfts-, Transit- oder frühere Aufenthaltsländer identifizieren zu können.
In unserem Vortrag stellen wir die Maßnahmen dar, die wir in verschiedenen Phasen des Forschungsprozesses ergriffen haben, um die Wiederverwendbarkeit, Reproduzierbarkeit und Replizierbarkeit der Daten zu maximieren und gleichzeitig das Risiko der Deanonymisierung zu minimieren. Dazu zählen beispielsweise die Aggregation von Daten und das gezielte Entfernen einzelner Variablen, die für andere Forschungsvorhaben weniger zentral, aber potenziell identifizierend sind. Darüber hinaus diskutieren wir die Aufbereitung und Dokumentation unseres Datensatzes, insbesondere (i) die Entwicklung von Standard Operating Procedures (SOPs) für Dateneingabe, Annotation und Dokumentation sowie (ii) die Durchführung von Standardisierungsworkshops für alle Mitglieder der verschiedenen Teilprojekte. Ziel unseres Beitrags ist es, Einblicke in den Umgang mit den konkurrierenden Anforderungen von Open Science einerseits und dem Schutz der Anonymität vulnerabler und diverser Populationen andererseits zu geben.
[Übersetzung mit ChatGPT]
Talk Slides for Download
The slides for the presentation can be downloaded HERE.

Das SpraNZiR-Projekt zu „Sprachkompetenzen neuzugewanderter Schülerinnen und Schüler im Regelunterricht“ und seine Teilprojekte
Informationen zu Open Science und zum SpraNZiR-Projekt
- Blogbeitrag zu Open Science (s. Tag Open Science für weitere Beiträge):
Open Science, Open Reproducible Research, Open Access, Open Data, Open Science Repositories und Open Source: Informationen zur Öffnung der Wissenschaft und Tipps zur Beteiligung von Kindern als Citizen Scientists - Projektbericht SpraNZiR (Mercator-Institut für Sprachförderung und Deutsch als Zweitsprache):
Marx, N., Barberio, T., Twente, L. R., Fuchs, M., Eisenbeiss, S., von Dewitz, N., & Bredthauer, S. (2024). Abschlussbericht zum Projekt „Sprachkompetenzen neuzugewanderter Schülerinnen und Schüler im Regelunterricht“(01.2021-06.2024). https://kups.ub.uni-koeln.de/75027/ - Für wissenschaftliche Projekte zur Verfügung gestellter Datensatz:
Marx, N., Barberio, T., Twente, L., Fuchs, M., Eisenbeiß, S., von Dewitz, N., Bredthauer, S. & Goltsev, E. (2025). Sprachkompetenzen neuzugewanderter Schülerinnen und Schüler im Regelunterricht (SpraNZiR) (Version 1) [Datensatz]. Berlin: IQB – Institut zur Qualitätsentwicklung im Bildungswesen. https://doi.org/10.5159/IQB_SpraNZiR_SUF_Off-site_v1 - Bisherige und zukünftige Blogbeiträge zum Projekt mit dem Tag SpraNZiR

Infobroschüre des SpraNZiR-Projekts zu Sprachkompetenzen neu zugewanderter Schülerinnen und Schüler im Regelunterricht
Mein persönlicher Sprachspinat-Tipp
Beim heutigen Sprachspinat-Tipp zur Verbindung von Sprachbildung, Naturbildung und Bildung für nachhaltige Entwicklung (BNE) geht es um Datenschutz als Thema für sprachsensible Bildung für nachhaltige Entwicklung im Schulgarten. Den Hintergrund bildet das UN-Nachhaltigkeitsziel (SDG) 16: Frieden, Gerechtigkeit und starke Institutionen. Hier geht es darum, „friedliche und inklusive Gesellschaften für eine nachhaltige Entwicklung fördern, allen Menschen Zugang zur Justiz ermöglichen und leistungsfähige, rechenschaftspflichtige und inklusive Institutionen auf allen Ebenen aufbauen“. Das Bundesministerium für wirtschaftliche Zusammenarbeit und Entwicklung (BMZ) macht auf seiner Webseite nähere Angaben zu diesem Ziel:
„Was wollen wir mit SDG 16 erreichen?
- Alle Formen der Gewalt und die gewaltbedingte Sterblichkeit überall deutlich verringern.
- Missbrauch und Ausbeutung von Kindern und alle Formen von Gewalt gegen Kinder beenden.
- Die Rechtsstaatlichkeit auf nationaler und internationaler Ebene fördern und den gleichberechtigten Zugang aller zur Justiz gewährleisten.
- Illegale Finanz- und Waffenströme sowie organisierte Kriminalität deutlich verringern.
- Korruption und Bestechung in allen ihren Formen erheblich reduzieren.
- Dafür sorgen, dass die Entscheidungsfindung auf allen Ebenen bedarfsorientiert, inklusiv, partizipatorisch und repräsentativ ist.
- Den öffentlichen Zugang zu Informationen gewährleisten und die Grundfreiheiten schützen.“
Im letzten Satz zeigt sich bereits der Widerspruch, den wir auch in unserem Vortrag diskutieren: Einerseits sollen Informationen öffentlich zugänglich sein, andererseits sollen Grundfreiheiten geschützt werden. Zu diesen gehören auch das Recht auf informationelle Selbstbestimmung – und damit auch Rechte am eigenen Bild und persönlichen Daten.

Bau einer WuPf-Wurmkompost-Pflanzenkiste am Jugendzentrum (JuZe) Köln Weiden
Themen wie Datenschutz und Digitalisierung stehen also in engem Zusammenhang mit SDG 16 und sollten altersangemessen aufgegriffen werden. Dies kann z.B. in einer Diskussion über Fotos von der Arbeit im Schulgarten oder im Jugendzentrumsgarten geschehen, wo u.a. die folgenden Fragen diskutiert werden könnten:
- Wem gehören Bilder (im Internet)?
- Welche Bilder von mir möchte ich selbst machen?
- Welche Bilder von mir dürfen andere von mir machen?
- Welche Bilder möchte ich anderen zugänglich machen?
- Wie sollte das geschehen?
- Was ist, wenn ich meine Meinung ändere?
- Wer kann mir helfen, wenn Bilder von mir gegen meinen Willen erscheinen?
- Was kann mir passieren, wenn ich Bilder von anderen gegen ihren Willen veröffentliche?
- Was ist der Unterschied zwischen Bildern von mir, Bildern von Tieren und Bildern von Pflanzen?
- Welche Informationen über mich gebe ich preis – und warum?
- Welche Spuren hinterlasse ich in digitalen Räumen?
- Welche Verantwortung trage ich im Umgang mit Daten anderer?
Bei der Beantwortung dieser Fragen kann man natürlich auch – je nach Alter – über (Fach-) Begriffe reflektieren, z.B. über Wörter wie anonym, pseudonymisiert, vertraulich, veröffentlicht, zugänglich etc. Zugleich wird deutlich, dass Wörter auch eine rechtliche Bedeutung haben können.
So bietet eine praktische Diskussion über Fotos im Schulgarten Anlass zu einer Diskussion über Datenschutz, Grundrechte, die Wirksamkeit von Sprache, SDG 16 und andere Aspekte der sozialen Nachhaltigkeit.
Vielen Dank an das WoReLa1-Team für die Workshoporganisation, dem Mercator-Institut für seine Unterstützung des SpraNZiR-Projekts, den SpraNZiR-Forschenden, die das Projekt gemeinsam gestaltet und unsere Präsentation mit vorbereitetet haben, den Kindern, Familien, Lehrkräften und Schulen, die bei unserer SpraNZiR-Studie mitgemacht haben – und allen viel Spaß beim Diskutieren über Open Science, Open Data und Datenschutz!

Die JuZe-Garten-AG am Werk – mit gespendeten Schubkarren und Eimern