Wer Artikel zu Spracherwerb und Spracherwerbstheorien lesen möchte, nach Lesetipps zu diesem Themen Ausschau hält oder Videos zu kindlichem Spracherwerb anschaut, sucht meist auch nach Beispielen von spracherwerbenden Kindern. Manche Menschen möchten auch gerne Aufnahmen von spracherwerbenden Kindern anhören, im Videoformat anschauen oder als Transkript, d.h. in verschriftlichter Form, lesen. Andere wollen Spracherwerbsdaten genauer betrachten und analysieren, z.B. für Hausarbeiten oder für Studien und Präsentationen in Schule, Studium oder Beruf. Und natürlich gibt es auch viele Menschen im Bildungsbereich, die Unterricht zum Thema „Spracherwerb“ geben und dafür Beispiele und Übungsaufgaben brauchen.
Die Spracherwerbsdaten, die man benötigt, um diese unterschiedlichen Wünsche und Bedürfnisse zu erfüllen, findet man in der internationalen CHILDES-Datenbank für Kindersprachdaten. Wer möchte, kann Spracherwerbsdaten auf der Webseite anschauen, kostenlos herunterladen oder sie mit den ebenfalls kostenlosen CLAN-Tools der CHILDES-Datenbank genauer analysieren. In der Spracherwerbsforschung wird die CHILDES-Datenbank viel verwendet. Dies erkennt man an den zahlreichen Veröffentlichungen und Dankesbriefen an das CHILDES-Team.
In der breiten Öffentlichkeit, in Schulen und in Einführungskursen an der Universität wird CHILDES im deutschsprachigen Raum leider immer noch zu wenig genutzt. Dies liegt u.a. an der mangelnden Bekanntheit von CHILDES und am Fehlen von detaillierten deutschsprachigen Anleitungen für die Datenbanknutzung. Dieser Blogbeitrag soll Abhilfe schaffen. Er ist der erste Teil einer vierteiligen Einführung in CHILDES mit den folgenden Themen:
- Einführung in CHILDES und Vorstellung von drei Sammlungen deutscher Kindersprachdaten (Leo-Korpus, Frog-Story-Korpus und Szagun-Korpus)
- das Finden, Anschauen und Herunterladen von Daten aus der CHILDES-Kindersprachdatenbank und einfache Textanalysen,
- die Auswertung von Wortlisten und Beispiellisten aus der CHILDES- Kindersprachdatenbank und
- die selbständige Erstellung von Wortlisten und Beispiellisten mit dem CLAN-Analysetool der CHILDES-Kindersprachdatenbank.
In diesem Blogbeitrag, der den ersten Teil der Beitragsserie darstellt, findet man
- einen Überblick über die CHILDES-Datenbank für Kindersprachdaten: Sprachen, Personengruppen und Datentypen
- Hinweise zur Verwendung von CHILDES-Daten
- Informationen zu den Leo-Daten in der CHILDES Datenbank
- Informationen zu den Frog-Story-Daten in der CHILDES Datenbank
- Informationen zu den Szagun-Daten in der CHILDES Datenbank
- eine Übung zur CHILDES-Datenbank
Und zum Schluss gibt es – wie immer auf dem Sprachspinat-Blog – meinen persönlichen Sprachspinat-Tipp.
Die CHILDES-Datenbank für Kindersprachdaten: Sprachen, Personengruppen und Datentypen
Das Child Language Data Exchange System (CHILDES) ist die weltweit größte Datenbank zum gestörten und nicht gestörten Spracherwerb von Kindern. CHILDES wurde 1984 von Brian MacWhinney und Catherine Snow geschaffen; und die ersten Aufnahmen reichen bis in die 1960er zurück. Der Hauptsitz von CHILDES befindet sich derzeit an der psychologischen Fakultät der Carnegie Mellon University in Pittsburgh, USA. Nebensitze findet man im belgischen Antwerpen und im japanischen Chukyo. Mittlerweile gehört CHILDES zum TalkBank-System, das Aufzeichnungen der Kommunikation zwischen Menschen, aber auch Tieren verfügbar macht. Talkbank stellt neben den CHILDES-Kindersprachdaten auch Daten von Erwachsenen bereit, insbesondere Gespräche, Zweitspracherwerbsdaten und Daten zu Sprachstörungen.
CHILDES enthält derzeit Transkripte, Audio- und Videoaufnahmen von Kindern aus mehr als hundert Forschungsprojekten mit mehr als 30 Sprachen; und es werden kontinuierlich neue Daten hinzugefügt. Dabei ist die Datenbasis sehr vielfältig: Man findet beispielsweise
- Korpora, d.h. Sammlungen von Aufnahmen bzw. Transkripten, von ein- und mehrsprachigen Kindern,
- Daten zu weit verbreiteten und gut untersuchten Sprachen wie Englisch, Deutsch. Französisch, Spanisch oder Mandarin Chinesisch, aber auch Daten von weniger untersuchten oder sogar vom Aussterben bedrohten Sprachen,
- Aufnahmen von Kindern ohne und mit Hörstörungen (s. z.B. Daten aus dem Szagun-Projekt zu Kindern mit Cochlea-Implantaten und einer Kontrollgruppe),
- Studien zu neurotypischen Kindern mit typischer Sprachentwicklung und „klinische“ Daten aus Studien zu Kindern mit Sprachstörungen und Studien zu nicht-neurotypischen Kindern (Autismusspektrum, Down Syndrom, Williams-Syndrom, Epilepsie),
- Projekte mit unterschiedlicher Aufnahmesituation, insbesondere Projekte, für die Kinder
- zuhause im Alltag aufgenommen wurden (z.B. das in diesem Beitrag vorgestellte deutschsprachige Leo-Projekt),
- zum Erzählen einer Geschichte aufgefordert wurden (z.B. das in diesem Beitrag vorgestellte sprach.- und kulturvergleichende Frog-Story-Projekt),
- beim Spielen im Labor beobachtet wurden (z.B. das in diesem Beitrag vorgestellte deutschsprachige Szagun-Projekt),
- Daten aus Studien mit unterschiedlichem Design:
- große Längschnittstudien mit „dichten“ Daten, für die man über mehrere Jahre hinweg dasselbe Kind mehrere Stunden pro Woche aufgenommen hat, z.B. das in diesem Blogeitrag vorgestellte deutschsprachige Leo-Projekt,
- Querschnittstudien mit vielen Kindern, die alle nur einmal aufgenommen wurden, z.B. das in diesem Blogbeitrag vorgestellte sprach.- und kulturvergleichende Frog-Story-Projekt,
- Längschnittstudien aus Langzeitprojekten mit einem oder mehreren Kindern, bei denen die einzelnen Aufnahmen eine Woche, einen Monat oder sogar mehr auseinanderliegen, z.B. das hier vorgestellte deutschsprachige Szagun-Projekt.
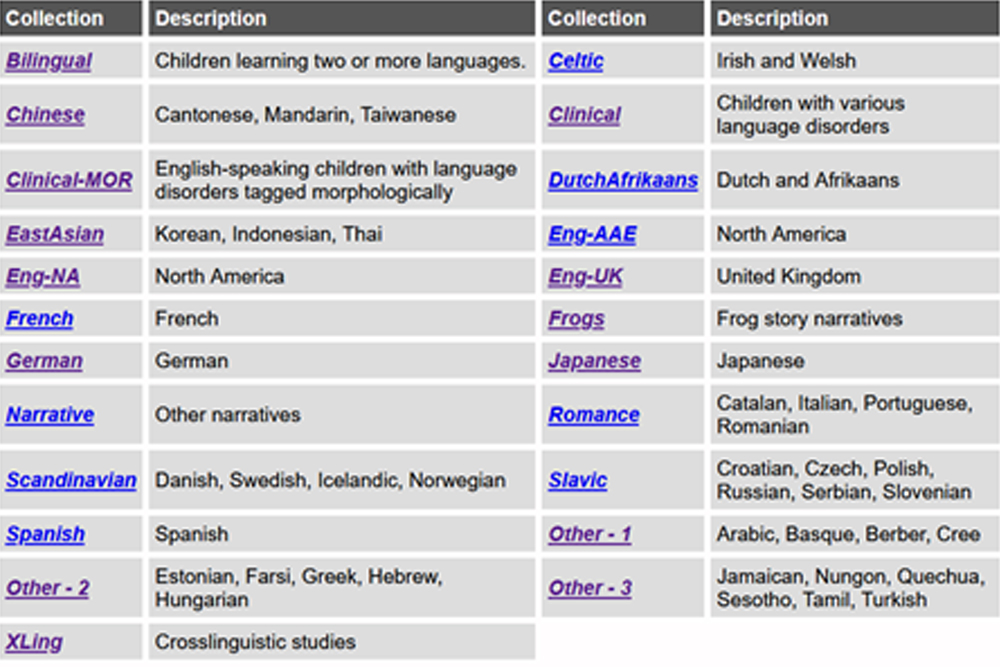
Korpus- und Sprachliste auf der CHILDES-Webseite
Die Verwendung von CHILDES-Daten
Alle CHILDES-Datenbankinhalte stehen unter der GNU General Public License und können auf der CHILDES-Webseite kostenlos angeschaut oder heruntergeladen werden. Dabei sind die Transkripte typischerweise frei zugänglich, während für viele Audio- und Videoaufnahmen aus Datenschutzgründen Zugangsbeschränkungen gelten. Wer CHILDES-Daten verwendet, sollte in Berichten über die Ergebnisse (auch in Hausarbeiten) stets die Publikation von Brian MacWhinney (2000) zitieren, damit die Analysen nachvollziehbar bleiben und die Arbeit des Datenbankteams anerkannt wird. Außerdem sollte man stets auch die Literaturangaben hinzufügen, die auf der Download-Seite für das entsprechende Korpus findet, d.h. für die spezifische Sammlung von Aufnahmen bzw. Transkripten aus einem bestimmten Projekt. Für die in diesem Blogbeitrag diskutierten Korpora sind die folgenden Angaben erforderlich:
- Literaturangabe für CHILDES:
- MacWhinney, B. (2000). The CHILDES Project: Tools for Analyzing Talk. 3rd Mahwah, NJ: Lawrence Erlbaum Associates.
- Literaturangabe für die deutschen Daten aus dem Frog-Story-Korpus:
- Berman, R. & Slobin, D.I. (Eds.) (In collaboration with Ayhan Aksu, Michael Bamberg, Virginia Marchman, Tanya Renner, Eugenia Sebastian, and Christiane von Stutterheim) (1994). Different ways of relating events in narrative: A crosslinguistic study. Hillsdale, NJ.: Erlbaum Associates.
- Literaturangaben für das Frogstory-Projekt:
- Projekt: Berman, R. A., & Slobin, D. I. (1994). Relating events in narrative: A crosslinguistic developmental study. Hillsdale, NJ: Lawrence Erlbaum Associates.
- verwendetes Bilderbuch: Mayer, M. (1969). Frog, where are you? New York: Dial Press.
- Literaturangabe für das Leo-Korpus:
- Behrens, H. (2006). The input-output relationship in first language acquisition. Language and Cognitive Processes, 21, 2-24.
- Literaturangaben für das Szagun-Korpus (Eine oder mehrere Angaben sind zu zitieren):
- Szagun, G. (2001). Learning different regularities: The acquisition of noun plurals by German-speaking children. First Language, 21, 109-141.
- Szagun, G. (2004). Learning by ear: On the acquisition of case and gender marking by German-speaking children with cochlear implants and with normal hearing. Journal of Child Language, 31, 1-30.
- Szagun, G., Stumper, B. Sondag, N. & Franik, M. (2007). The acquisition of gender marking by young German-speaking children: Evidence for learning guided by phonological regularities. Journal of Child Language, 34, 445-471.
- Szagun, G. (2010). Regular/irregular is not the whole story: The role of frequency and generalization in the acquisition of German past participle inflection. Journal of Child Language, 37, 1-32.
- Szagun, G. & Stumper, B. (2012). Age or experience? The influence of age at implantation, social and linguistic environment on language development in children with cochlear implants. Journal of Speech, Language, and Hearing Research, 55, 1640-1654.
- Szagun, G. & Schramm, S. A. (2016). Sources of variability in language development of children with cochlear implants: age at implantation, parental language, and early features of children’s language construction. Journal of Child Language, 43, 505-536.
Wer die CHILDES-Datenbank für wissenschaftliche Projekte oder Bildungsprojekte einsetzt, kann das CHILDES-Team auch über Publikationen informieren und alle, die das Korpus verwenden können ihre Unterstützung durch Briefe zeigen. Das CHILDES-Team sammelt Zitationen in wissenschaftlichen Publikation und Unterstützungsbriefe. Die entsprechenden Listen helfen dabei, Forschungsförderungsinstitutionen davon zu überzeugen, die Datenbank auch weiterhin finanziell zu unterstützen. So kann man durch Zitieren und Unterstützungsbriefe zum Erhalt der Datenbank beitragen, auch ohne für ihre Verwendung direkt zu bezahlen.
Die Leo-Daten in der CHILDES Datenbank
Die Beschreibung im folgenden Abschnitt ist eine deutsche Kurzform der englischen Beschreibung auf der CHILDES-Webseite. Beispiel 1 gibt einen ersten Eindruck von den Leo-Daten. Spezielle Markierungen sind hier ausgelassen (zu solchen Markierungen s. den zweiten Blogbeitrag zur CHILDES-Datenbank, der sich mit dem sog. CHAT-Datenformat für Transkripte in der CHILDES Datenbank befasst). Lediglich die [*]-Markierung für die Verwendung einer nicht-zielsprachlichen Form und die in eckigen Klammern angegebene zielsprachliche Form wurden beibehalten.CHI ist das Kind, MUT die Mutter.
Beispiel 1: Leo-Korpus, Transkript 020411.cha, Alter: 2 Jahre, 4 Monate, 11 Tage
*CHI: eine Wasseramsel .
*MUT: wusst(e) ich auch nich(t) , dass es sowas gibt .
*MUT: siehste [: siehst du] .
*CHI: und die hat antgewortet [: geantwortet] [*] .
*MUT: was hat die ?
*CHI: antgewortet [: geantwortet] [*] .
*MUT: genau , die hat geantwortet .
*CHI: ja. ja.
*MUT: ja .
*CHI: ja .
*MUT: genau .
Die beteiligten Personen
Das Leo-Projekt beruht auf einer Längschnittstudie mit „dichten“ Daten, die vom Max-Planck-Institut für evolutionäre Anthropologie durchgeführt wurde. Der Vater (in allen Transkripten mit VAT markiert) von Leo (CHI) ist Akademiker, seine Mutter (MUT) arbeitete nach Abitur und Lehre als Buchhändlerin, während der Studie in Teilzeit. Beide Eltern sprechen dialektfreies Standarddeutsch. Leo begann mit 2 Jahren und 10 Monaten, in den Kindergarten zu gehen, und bekam mit 3 Jahren und drei Monaten eine Schwester, Wilhelmine (WIL). In einem Teil der Aufnahmen wirkt auch eine Studentenassistentin (MEC) mit, die mindestens einmal in der Woche zum Babysitten kam, als Leo zwischen zwei und drei Jahre alt war. Ein- bis zweimal in der Woche machte der Vater die Aufnahmen.
Die Aufnahmen
Die Dateinamen geben Leos Alter im Format JJMMTT an. Im Transkript findet man das Alter im Format J;MM.TT. Die Aufnahmen fingen mit technischen Probeaufnahmen an, als Leo 1 Jahr, 11 Monate und 12 Tage alt war (Altersangabe im Text der Aufnahme: 1;11.12, Aufnahmename: 011112.cha). Die eigentliche Studie begann mit Leos zweitem Geburtstag und endete, als Leo 4 Jahre, 11 Monate und 5 Tage alt war (Altersangabe im Text der Aufnahme: 4;11.05, Aufnahmename: 041105.cha). Pro Woche wurden fünf Stunden Aufnahmen gemacht, eine Stunde davon mit Video, die übrigen als reine Audioaufnahmen. Im ersten Jahr wurden zusätzlich zu den Audio- bzw. Videoaufnahmen noch Tagebuchnotizen zu besonders innovativen oder komplexen Äußerungen gemacht. Diese Äußerungen wurden von den beteiligten Erwachsenen möglichst direkt nach der Äußerung wiederholt und dabei in ein Diktaphon gesprochen. Solche Tagebuchnotizen sind in den Transkripten mit [- diary] markiert. Alle Aufnahmen fanden im Haushalt der Familie oder – in den Ferien – in einem Hotel statt.
Die Aufnahmen begannen, als Leo mit einem Jahr und elf Monaten erstmals einzelne Wörter miteinander verband und einen aktiven Wortschatz von ca. 340 Wortformen hatte. Zu diesem Zeitpunkt zeigte sich auch der erste Kontrast zwischen einer Einzahl/Singular-Form und einer Mehrzahl/Plural-Form. Leo begann relativ spät zu sprechen; und sein Wortschatz war schon recht groß, bevor er anfing, Sätze zu bilden. Die grammatische Entwicklung schritt dann aber relativ schnell voran.
Zugang zu den Daten und weitere Informationen
Die Daten von Leo können auf der Webseite der CHILDES-Datenbank angesehen bzw. heruntergeladen werden: https://childes.talkbank.org/access/German/Password/Leo.html. Dort finden sich auch die entsprechenden Audio- bzw. Videodateien der Sprachaufnahmen. Diese sind aber nicht alle öffentlich zugängig. Wenn man die Transkripte in Word öffnet, sieht man, dass die Aufnahme und die Angaben zur Position in der Mediendatei mit „%snd:“ gekennzeichnet sind. Mehr Informationen zum Leo-Korpus findet man in der o.a. Publikation von Heike Behrens (2006).
Die „Frog Story“-Daten in der CHILDES Datenbank
Die Beschreibung im folgenden Abschnitt ist eine deutsche Kurzform der englischen Beschreibung auf der CHILDES-Webseite.
Das Frog-Story-Projekt
Für das Frog-Story-Projekt wurden Kinder (und später auch Erwachsene) aus verschiedenen Ländern dazu aufgefordert, Mercer Mayers Bildergeschichte “Frog, where are you?” in ihrer eigenen Sprache nachzuerzählen. So sollten vergleichbare Erzählungen erhoben werden, die es ermöglichen, unterschiedliche Altersgruppen, Sprachen mit unterschiedlicher Struktur und Kulturen mit unterschiedlicher Erzähltradition zu vergleichen.
Das Bilderbuch von Mercer Mayer besteht aus 24 Bildern und erzählt eine Geschichte von einem Jungen und einem Frosch. Die Bilder des Buches und die Anleitungen für die Datenerhebung, die Ruth Berman und Dan Slobin für das Projekt entwickelt haben, kann man auf der CHILDES-Webseite finden.
Die folgenden Beispiele zeigen den Anfang einer bildbasierten Erzählung aus dem Frog-Story-Korpus – einmal von einem dreijährigen Kind und einmal von einer zwanzigjährigen Kontrollperson. Beide werden mit *CHI als unterrsuchte Person gekennzeichnet. Anmerkungen zu Bildern etc. aus dem Transkript wurden hier bei der Präsentation der beiden Beispiele ausgelassen. Es ist zu beachten, dass im Frog-Story-Korpus Pünktchen bei Umlauten weggelassen werden und auch keine Umschreibung erfolgt (also z.B. keine Verwendung von ue statt ü). Man kann also am Transkript nicht erkennen, ob jemand hupft oder hüpft gesagt hat.
Beispiel 2: Frog-Story-Korpus, Anfang von Transkript 03b.cha, Alter: 3 Jahre
*CHI: da ist der Frosch drin .
*CHI: da kuckt der rein .
*CHI: der Junge auch .
*CHI: und da schlafen die .
*CHI: und da hupft der Frosch raus .
*CHI: da wachen die wieder auf .
*CHI: da ist der Frosch weg .
*CHI: und da schlaft der .
*CHI: und da ist der aufgewacht …
Beispiel 3: Frog-Story-Korpus, Anfang von Transkript 20b.cha, Alter: 20 Jahre
*CHI: also ich mocht jetzt die die Geschichte erzahlen von dem kleinen
Hund der Frau Frosch und dem kleinen Hans .
*CHI: die beiden die wohnten in trautem Heim zusammen .
*CHI: der Frosch war im kleinen Glas untergebracht die Frau Frosch .
*CHI: und vertrug sich gut mit dem Herrn Hund und dem kleinen Hansi .
*CHI: nachts mussten sie alleine schlafen .
*CHI: der Hund liegt bei seinem Herrchen Hansi .
*CHI: und Frau Frosch nutzt die Gelegenheit .
*CHI: um mal aus ihrem Glas herauszusteigen .
*CHI: als am fruhen Morgen dann Hans und der Hund aufwachen .
*CHI: bemerken sie zu ihrem grossen Schrecken .
*CHI: dass Frau Frosch durch geoffnete Fenster nach draussen weggelaufen
ist …
Aufnahmen und Dateinamen
Die Daten wurden für alle Sprachen und Altersgruppen auf dieselbe Weise erhoben: Jedes Kind wurde einzeln aufgenommen. Dabei sollte das Kind zunächst das ganze Buch anschauen und erst danach die Geschichte erzählen, während es die einzelnen Bilder anschaute. So konnte das Kind vor dem Erzählen einen Überblick über die Gesamtgeschichte erhalten; und die Gedächtnisbelastung konnte so gering wie möglich gehalten werden. Die anwesenden Erwachsenen wurden dazu angehalten, möglichst wenig zu sagen und nur neutrale minimale Kommentare zu geben (z.B. Kopfnicken oder ein einfaches okay).
Für die meisten Sprachen wurden Gruppen von jeweils 12 Personen für die jeweilige Alterststufe aufgenommen. Die Dateinamen sind eine Kombination des Alters mit einem Buchstaben (z.B. 03a). Die Bilder sind im Transkript mit „@g“ markiert und nummeriert.
Die folgende Abbildung zeigt die CHILDES-Seite zum Frog-Story-Projekt mit den Informationen zu Sprachen, Altersgruppen sowie zur Anzahl der teilnehmenden Personen (N). Wie man hier sieht, sind für das deutschsprachige Frog-Story-Korpus keine Video- oder Audio-Dateien verfügbar.
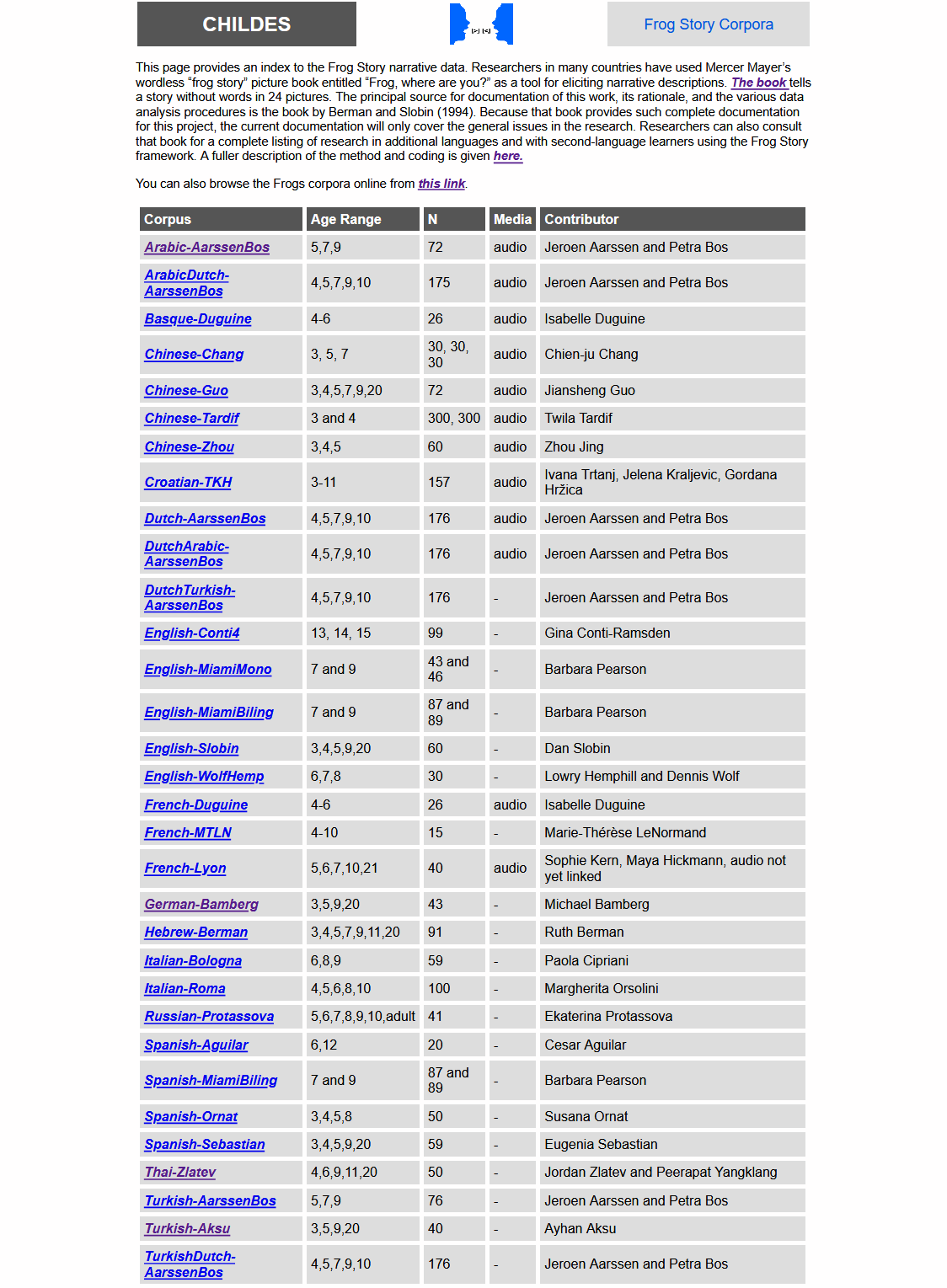
Korpus- und Sprachliste für das Frog-Story-Projekt auf der CHILDES-Webseite
Zugang zu den Daten und weitere Informationen
Die Daten des Frog-Story-Projektes sowie das Bilderbuch und die Anleitungen können auf der Webseite der CHILDES-Datenbank angesehen bzw. heruntergeladen werden: https://childes.talkbank.org/access/Frogs/ .
Auf der Experimentalfieldlinguistics-Webseite findet man eine fortlaufend aktualisierte Liste mit Publikationen und weiteren Informationen zur Frog-Story und anderen Bild- und Videomaterialien, die für die Datenerhebung in sprachwissenschaftlichen Projekten verwendet werden. Außerdem gibt es auch eine YouTube-Playliste zum Frog-Story-Korpus, die u.a einen englischsprachigen Bericht von Dan Slobin über das Projekt enthält.
Die Szagun-Daten in der CHILDES Datenbank
Die folgende Beschreibung ist eine deutsche Kurzform der englischen Beschreibung auf der CHILDES-Webseite. Beispiel 4 aus dem Szagun-Korpus zeigt, wie wichtig es ist, nicht nur Kinder aufzunehmen, sonderen auch ihren „Input“ von Erwachsenen. Hier sieht man, wie Erwachsene ihre Äußerungen wiederholen und variieren, wenn sie mit jüngeren Kindern sprechen. CHI ist das Kind, MOT die Mutter und GIS ist Gisela Szagun.
Beispiel 4: Anna (1;04.05) zeigt auf einen Spiegel*
*CHI: da da.
*GIS: ja das sind wir da.
*GIS: das bist du.
*GIS: da bin ich, und das is(t) deine Mama.
*CHI: da ba .
%com: Ann rennt durchs Zimmer. Mot und Ann malen mit Kreide an der Tafel.
*MOT: komm mal her.
*MOT: Anna, komm mal her.
*MOT: woll(e)n wir mal was malen?
*MOT: xxx.
*MOT: Anna, damit kann man malen.
Das Szagun-Korpus entstand in der Zeit von 1996 bis 2000 und besteht aus 2 Teilen: einem Korpus mit 212 Aufnahmen von 22 Kindern ohne Hörstörungen und mit typischer Sprachentwicklung und einem Korpus mit 210 Aufnahmen von 22 tauben Kindern mit Cochlear-Implantaten.
Alle 22 Kinder mit Cochlear-Implantaten waren bereits vor dem Beginn der Sprachentwicklung taub, 20 von Geburt an und 2 durch Meningitis im ersten Lebensjahr. Die Implantierung erfolgte im Alter von 1;2 bis 3;10. Jedes der Kinder mit Cochlear-Implantat wurde mit einem Kind mit typischer Sprachentwicklung gematcht, so dass die beiden Kinder jeweils dasselbe Ausgangssprachlevel kann man das auch auf Deutsch sagen? hatten. Dabei erfolgte der Vergleich auf der Basis der mittleren Äußerungslänge und der mittleren Anzahl von Wörtern. Jedem der Kinder mit Cochlear-Implantat wurde ein Höralter zugewiesen. Dabei war der Startpunkt (O Jahre) die erste Anpassung des Implantats an das Hörniveau des Kindes, 6 Wochen nach Implantierung.
Aufnahmen und Dateinamen
In allen Aufnahmen spielen die Kinder einzeln mit Erwachsenen (Elternteil in einem Projekt-Teammitglied) in einem Spielzimmer an der Universität Oldenburg bzw. im Implantierungszentrum Hannover. Dabei hatten die Kinder die freie Auswahl aus den dort vorhandenen Spielmaterialien. Diese waren für beide Gruppen ähnlich (z.B. Autos mit Garage und Parkhaus, Zoo oder Bauernhof mit Tieren, Bilderbücher oder Puzzles sowie diverse Tierfiguren und kleinere Objekte).
Die 22 Kinder mit typischer Sprachentwicklung wurden mindestens fünfmal für 2 Stunden aufgenommen, im Alter von 1;4, 1;8, 2;1, 2;5, 2;10 (J;MM). 6 der 22 Kinder wurden 22 mal aufgenommen (ca. alle 5 bis 6 Wochen). Bei den Aufnahmen im Alter von 1;4, 1;8, 2;1 und 2;5 wurden mindestens 500 an das Kind gerichtete Äußerungen von Erwachsenen wörtlich transkribiert, manchmal auch mehr. Das Ende der wörtlichen Transkription wurde auf der mit %com gekennzeichneten Kommentarline markiert. Die danach auftretenden Äußerungen von Eltern oder anderen Erwachsenen wurden nur dann transkribiert, wenn es zum Verständnis der Kinderäußerung erforderlich war.
Die 22 Kinder mit Cochlear-Implantat wurden alle mindestens fünfmal in 18 Monaten für 1,5 und 2 Stunden aufgenommen. Dabei betrugen die Abstände zwischen den fünf Aufnahmen für den Gruppenvergleich jeweils 4,5 Monate und das Höralter zum Zeitpunkt der Aufnahmen war 0;5, 0;9.14, 1;2, 1;6.14 und 1;11. Zusätzlich zu diesem Gruppenvergleichsdatensatz wurden 11 der Kinder mit Cochlear-Implantat häufiger aufgenommen (10 bis 14 Aufnahmen). Die übrigen 9 Kinder aus der Implantatgruppe wurden auch noch nach dem Vergleichszeitraum aufgenommen, so dass 6 bis 9 Aufnahmen für diese Kinder vorliegen. Bei den Aufnahmen im Höralter von 0;5, 0;9.14, 1;2 and 1;6.14 wurden mindestens 500 an das Kind gerichtete Äußerungen von Erwachsenen wörtlich transkribiert, manchmal auch mehr. Dabei wurde wie bei der Kontrollgruppe vorgegangen.
Für alle Aufnahmen liegen Audiodateien vor. Dabei wurden allerdings keine Verbindungen zwischen einzelnen Äußerungen und der entsprechenden Stelle im Transkript hergestellt. Die Namen der Audiodateien setzen sich zusammen aus drei Buchstaben für den Namen des Kindes und drei Zahlen für Jahr und Monat des Alters bzw. Höralters (z.B. sil202-2.wav für die zweite Hälfte der Aufname von Silia im Alter von 2 Jahren und 2 Monaten). Einige Audiodateien fehlen aus technischen Gründen.
Die Dateinamen für die Transkripte ergeben sich aus dem (Hör)alter, z.B. 050627.cha für eine Aufnahme mit dem Höralter von 5 Jahren, 6 Monaten und 27 Tagen. Zwischen den Aufnahmen für die einzelnen Kinder wird durch die Speicherung in unterschiedlichen Verzeichnissen auf der Webseite bzw. im herunterladbaren Dateiordner gesorgt.
Zugang zum Szagun-Korpus
Die Transkripte aus dem Szagun-Korpus kann auf der Webseite der CHILDES-Datenbank angesehen bzw. heruntergeladen werden: https://childes.talkbank.org/access/German/Szagun.html. Dort gibt finden sich auch die entsprechenden Audiodateien der Sprachaufnahmen. Mehr Informationen zum Szagun-Korpus findet man in den Publikation von Gisela Szagun, die auf der Download-Seite für das Szagun-Korpus angegeben sind.
Übung zur CHILDES-Datenbank
In der Spracherwerbsforschung werden oft generelle Aussagen über den Spracherwerb gemacht, die für alle Sprachen bzw. Kulturen gelten sollen. Zur Bewertung solcher Aussagen bräuchte man repräsentative Datensammlungen, bei denen die Verteilung von Sprachen und Kulturen der Verteilung von Sprachen und Kulturen in der Weltbevölkerung entspricht. Es sollten also z.B. nicht bestimmte Sprachen dominieren, die nur von einem relativ geringen Anteil der Weltbevölkerung als Erstsprache erworben werden. Stellen Sie fest, ob dies für die CHILDES-Datenbank derzeit der Fall ist. Verschaffen Sie sich hierzu einen Überblick über den aktuellen Stand der CHILDES-Datenbank:
- Für welche Sprachen wurden Daten archiviert?
- Wie groß ist dabei jeweils die Menge an Daten?
- Für welche Sprachen bzw. Gruppen von Kindern wurden klinische Daten erhoben, d.h. Daten von Kindern mit Sprach- oder Hörstörungen oder nicht-neurotypischer Entwicklung?
- Welcher Altersbereich wird durch die dokumentierten Daten für die einzelnen Sprachen abgedeckt?
- In welchen Situationen wurde jeweils aufgenommen?
- Wie verteilen sich die dokumentierten Sprachen über die Kontinente?
- Wie verteilen sich die dokumentierten Sprachen über Sprachfamilien?
Zur Diskussion der aktuellen Situation und zu Versuchen, eine repräsentative Datenbasis zu gewährleisten, s. den Sprachspinat-Blogbeitrag zu aktuellen Trends in der Spracherwerbsforschung.
Mein persönlicher Sprachspinat-Tipp
Auf der CHILDES-Webseite gibt es Einführungs- und Unterrichtsmaterialien auf Englisch. Am besten lernt man die CHILDES-Datenbank aber kennen, indem man auf die Seite mit dem Überblick über die Sprachen und Korpora geht und auf interessant erscheinende Links klickt. Dann kann man auf den entsprechenden Korpusseiten die Links zu „browsable data“ finden und sich Transkripte anschauen oder Aufnahmen anhören. Wer weitergehende Analysen durchführen will, findet in den nächsten Blogbeiträgen zur CHILDES-Datenbank Anregungen und Informationen. Und wer mehr über Spracherwerbsforschung und Spracherwerb erfahren möchte, findet auf dem Sprachspinat-Blog weitere Beiträge, LIteraturangaben sowie Links zu Webseiten, Projekten und Videos.
Pingback: Kindersprachdaten aus der CHILDES-Datenbank anschauen und analysieren. Teil 2: Wie kann man in der CHILDES-Datenbank für Kindersprache Aufnahmen und Transkripte von Kindern finden, anschauen und herunterladen und einfache Analysen zum Spracherwerb durchf
Pingback: Kindersprachdaten aus der CHILDES-Datenbank anschauen und analysieren. Teil 2: Wie kann man in der CHILDES-Datenbank für Kindersprache Aufnahmen und Transkripte von Kindern finden, anschauen und herunterladen und einfache Analysen zum Spracherwerb durchf