Dieser Blogbeitrag ist der zweite Teil einer vierteiligen Einführung in Kindersprachanalysen mit Aufnahmen aus der internationalen CHILDES-Datenbank für Kindersprachdaten:
- Blogbeitrag 1: Einführung in CHILDES und Vorstellung von drei Sammlungen deutscher Kindersprachdaten (Leo-Korpus, Frog-Story-Korpus und Szagun-Korpus),
- Blogbeitrag 2: das Finden, Anschauen und Herunterladen von Daten aus der CHILDES-Kindersprachdatenbank und einfache Textanalysen,
- Blogbeitrag 3: die Auswertung von Wortlisten und Beispiellisten aus der CHILDES- Kindersprachdatenbank und
- Blogbeitrag 4: die selbständige Erstellung von Wortlisten und Beispiellisten mit dem CLAN-Analysetool der CHILDES-Kindersprachdatenbank.
Nach der generellen Einführung in CHILDES und der Vorstellung von drei Kinderspachsammlungen (Leo-Korpus, Frog-Story-Korpus und Szagun-Korpus) im ersten Blogbeitrag findet man im heutigen, zweiten Blogbeitrag:
- eine Einführung in den Aufbau und das sog. CHAT-Format der CHILDES-Transkripte, d.h. der verschriftlichten Kindersprachaufnahmen in der CHILDES-Datenbank,
- eine Anleitung zum Anschauen und Analysieren von Kindersprachdaten auf der CHILDES-Webseite,
- eine Anleitung zum Herunterladen von Kindersprachdaten und zum Anschauen und Analysieren der heruntergeladenen Transkripte in Textverarbeitungsprogrammen sowie
- Übungen zur Analyse von Kindersprachtranskripten.
Und zum Schluss gibt es – wie immer auf dem Sprachspinat-Blog – meinen persönlichen Sprachspinat-Tipp. Die Literatur- und Downloadangaben zu den drei verwendeten Korpora und Hinweise zu ihrer Verwendung in Unterricht und Forschung findet man in Blogbeitrag 1 zu CHILDES.
Das CHAT-Format der Transkripte in der CHILDES-Kindersprachdatenbank
Das CHAT-Format (Codes for the Human Analysis of Transcripts Computerized Language Analysis) ist das Format, in dem die herunterladbaren Transkripte, d.h. die verschriftlichten Sprachaufnahmen, in der CHILDES-Kindersprachdatenbank vorliegen. Das CHAT-Format unterstützt die Computeranalyse durch das Analysetool CLAN, das u.a. für die Erstellung von Wort- und Beispiellisten verwendet wird und im vierten Sprachspinat-Blogbeitrag zu CHILDES näher beschrieben wird.
Das CHAT-Format ist nicht nur für CLAN-Analysen erforderlich; es hilft auch bei der Durchsuchung von Transkripten mit Textverarbeitungsprogramm wie Word. Außerdem macht dieses Format es einfacher, die Transkripte zu verstehen, wenn man keinen Zugang zu den entsprechenden Audio- oder Videodaten hat und die aufgenommenen Personen und ihre Lebensumstände nicht näher kennt:
- Im CHAT-Format beginnt jede Äußerung mit einem Kürzel für die Person, die diese Äußerung gemacht hat, z.B. *CHI für das Kind, *MUT bzw. *MOT für die Mutter und *VAT bzw. *FAT für den Vater. Dadurch kann man Sprachanalysen für einzelne Personen durchführen, auch wenn man nicht sehen oder hören kann, wer gerade spricht Dies ist z.B. erforderlich, wenn man verglichen möchte, welchen Input das Kind von der Mutter erhält und welchen Input das Kind vom Vater bekommt.
- In CHAT-Transkripten kann man mit speziellen Markierungen Pausen, Abbrüche, Wiederholungen oder Abweichungen von der Zielsprache markieren. Beispielsweise kann man nicht-zielsprachliche Wortformen mit „[*]“ kennzeichnen. Dies ermöglicht es, nach Fehlern zu suchen, wenn man noch nicht genau weiß, welche Fehler zu erwarten sind. So kann man in Transkripten auch eher unerwartete Fehler wie antgewortet statt geantwortet Solche Fehler würde man nicht gezielt suchen – und auch nicht so einfach in größeren Datenmengen entdecken, wenn man nicht nach „[*]“ suchen könnte.
- CHAT-Transkripten enthalten häufig nicht nur die Zeilen mit den einzelnen sprachlichen Äußerungen. Sie können auch weitere Zeilen mit Zusatzinformationen enthalten, z.B. Informationen über die Wortart der einzelnen Wörter in einem Transkript. Solche sog. Part-of-Speech (POS) Annotationen erlauben es, nicht nur nach Einzelwörtern wie für, wegen, in oder mit zu suchen, sondern nach allen Wörtern mit derselben grammatischen Kategorie, z.B. nach allen Präpositionen. Darüber hinaus kann man das Transkript durch spezielle Zeilen mit Kontextinformationen und Erklärungen zu den einzelnen Äußerungen ergänzen. Beispielsweise kann man bei Äußerungen wie das von gestern war besser auf einer Erklärungszeile erklären, worauf das Kind sich mit das von gestern
Die generellen Regeln für die Verwendung spezieller Markierungen und Annotationen findet man im CHAT-Handbuch. Alle spezielle Regelungen für einzelne Korpora findet man in den Beschreibungen auf den Downloadseiten für die jeweiligen Korpora (s. Blogbeitrag 1 für die zentralen Punkte zu den hier diskutierten Korpora). Im Folgenden werden die wichtigsten CHAT-Konventionen erläutert, mit einem Schwerpunkt auf den Konventionen, die man für die Arbeit mit den drei Korpora benötigt, die im ersten Blogbeitrag zu CHILDES vorgestellt wurden, d.h. für die Arbeit mit dem Leo-Korpus, dem Frog-Story-Korpus und dem Szagun-Korpus:
Dateinamen für Transkripte im CHAT-Format
Die Dateinamen in Längsschnittstudien geben normalerweise das Alter des untersuchten Kindes an, typischerweise im Format JJMMTT (z.B. „041105.cha“). Dies ist z.B. im Leo-Korpus oder im Szagun-Korpus der Fall. Der Name des Kindes ist dabei nicht im Dateinamen erkennbar. So können zwei Dateien denselben Namen haben, obwohl sie von verschiedenen Kindern stammen und andere Inhalte haben. Daher muss man in solchen Fällen Aufnahmen von verschiedenen Kindern in unterschiedlichen Verzeichnissen („Foldern“ oder „Directories“) speichern, um die Transkripte dem betreffenden Kind zuordnen zu können.
Anders sieht dies bei Querschnittstudien aus, wo es für mehrere Kinder im selben Altersbereich jeweils nur eine Aufnahme gibt. Dies ist z.B. beim Frog-Story-Korpus der Fall, wo drei Gruppen von Kindern und eine erwachsene Kontrollgruppe untersucht werden (3, 5, 9 und 20 Jahre). Hier wird für jede untersuchte Person nur das Alter in Jahren angegeben, ergänzt durch ein Kürzel zur Unterscheidung der Aufnahmen verschiedener Personen, die im selben Verzeichnis liegen. So ist z.B. „03a.cha“ der Name für eine Transkriptdatei für die Erzählung der Frog Story durch das erste Kind in der Altersgruppe der Dreijährigen.
Der Aufbau von Transkripten im CHAT-Format
Transkripte im CHAT-Format sind reine Textdateien mit ASCII-Format. d.h. ohne Formatierungen wie Fett- oder Kursivdruck oder Überschriften mit speziellen Schrifttypen bzw. ‑größen. Jedes Transkript beginnt mit @BEGIN und endet mit @End. Dazwischen findet man drei verschiedene Typen von Zeilen:
- Kopfzeilen (headers) mit Metadaten, d.h. Informationen über die betreffende Aufnahme (z.B. über die beteiligten Personen und die verwendete Sprache,
- unabhängige Zeilen oder Hauptzeilen (independent/main tiers) mit den transkribierten Äußerungen der einzelnen Personen und
- abhängige Zeilen (dependent tiers) mit zusätzlichen Angaben (z.B. zum außersprachlichen Kontext oder zu den verwendeten Wortarten).
Kopfzeilen (Headers)
Die Kopfzeilen (headers) mit den Metadaten über die betreffende Aufnahmen beginnen stets mit dem Symbol „@“. Die folgenden Beispiele zeigen Kopfzeilen aus den drei deutschsprachigen Korpora, die im ersten Sprachspinat-Blogbeitrag zu CHILDES beschrieben wurden und in den übrigen CHILDES-Blogbeiträgen für Übungen verwendet werden.
Beispiel 1: Kopfzeilen aus der Transkriptdatei 041105.cha im Leo-Korpus
@Begin
@Languages: deu, eng
@Participants: CHI Leo Target_Child , MUT Maren Mother , VAT Father Father, WIL Wilhelmine Sister
@ID: deu|Leo|CHI|4;11.05|male|group|MC|Target_Child|education||
@ID: deu|Leo|MUT|30;00.00|female|group|MC|Mother|Abitur_Lehre||
@ID: deu|Leo|VAT|35;00.00|male|group|MC|Father|university||
@ID: deu|Leo|WIL|1;08.09|female|group|MC|Sister|education||
@Media: 041105, audio
@Date: 08-FEB-2002
@Comment: Beginn Tonband
@Situation: spät nachmittags , CHI , MUT und WIL , Leo gibt in dieser Aufnahme oft merkwürdige Rülpslaute von sich , was ihm offenbar gefällt
@Types: long, toyplay, TD
Beispiel 2: Kopfzeilen aus der Transkriptdatei 03a.cha im deutschsprachigen Frog-Story-Korpus
@Begin
@Languages: deu
@Participants: CHI Target_Child
@ID: deu|German-Bamberg|CHI|3;09.||||Target_Child|||
@G: 01
@Types: cross, narrative, TD
Beispiel 3: Kopfzeilen aus der Transkriptdatei 030520.cha im Szagun-Korpus (Kinder mit Cochlea-Implantat, CI = Cochlear Implant)
@Begin
@Languages: deu
@Participants: CHI Adriane Target_Child , MOT Mother , GIS Gisela Investigator
@ID: deu|Szagun|CHI|3;05.20|female|||Target_Child|||
@ID: deu|Szagun|MOT||female|||Mother|||
@ID: deu|Szagun|GIS|||||Investigator|||
@Media: 030520, audio, missing
@Situation: Room at Cochlear Implant Center
@Transcriber: Gisela Szagun
@Types: long, toyplay, CI
Beispiel 4: Kopfzeilen aus der Transkriptdatei 010405.cha im Szagun-Korpus (Kinder aus der Kontrollgruppe, TD = typically developing)
@Begin
@Languages: deu
@Participants: CHI Anna Target_Child , MOT Mother , GIS Gisela Investigator
@ID: deu|Szagun|CHI|1;04.05|female|||Target_Child|||
@ID: deu|Szagun|MOT|||||Mother|||
@ID: deu|Szagun|GIS|||||Investigator|||
@Media: 010405, audio, missing
@Situation: Playroom at University
@Transcriber: Claudia Steinbrink
@Types: long, toyplay, TD
Die folgenden Typen von Kopfzeilen tauchen in den drei vorgestellten Korpora auf, aber auch in vielen anderen:
- @Languages
Die in den drei vorgestellten Korpora untersuchten Kinder sind zwar deutschsprachig, aber auch hier ist es z.T. sinnvoll, die Sprache für einzelne Transkripte hinzuzufügen. In der Beispieldatei für Leo findet man z.B. neben deutschen Äußerungen auch englische Liedtexte (Old MacDonnald had a farm) - @ID und @Participants
Hiermit werden die Kürzel eingeführt, die man in den folgenden Hauptzeilen für die einzelnen Personen in den betreffenden Transkripten verwendet. Darüber hinaus werden Zusatzinformationen über diese Personen und ihre jeweilige Rolle präsentiert. Beim Vergleich der Beispiele erkennt man, dass nicht einfach Kürzel der Namen für Kinder wie Leo oder Adriane verwendet werden, sondern stets der Personenkode CHI. Dies ermöglicht es, Suchbefehle zu verwenden, die CHILDES Kindersprachdaten in verschiedenen Korpora durchsuchen können, unabhängig davon, wer das betreffende Kind in den untersuchten Aufnahmen ist. Da die Informationen über die Identität der untersuchten Personen aber nicht einfach weggelassen wird, sondern in der Kopfzeile des Transkripts steht, kann man gezieltere Suchen in den Daten einzelner Personen durchführen, auch wenn für alle Kinder dasselbe Kürzel, nämlich CHI, verwendet wird. - @Media
Hier findet man die Dateinamen der Audio- bzw. Videodateien, die jeweils zum entsprechenden Transkript gehören. Bei manchen Korpora sind diese Dateien generell nicht verfügbar, entweder aus Datenschutzgründen, oder weil die Aufnahmen schon sehr lange zurückliegen. Bei sehr alten Aufnahmen, die noch mit Ton- bzw. Videobändern gemacht wurden, konnte man nämlich oft keine digitalen Kopien der Aufnahmen machen, solange die alten Bänder noch intakt waren und zur Digitalisierung bereitstanden. In diesem Falle gibt es in den Kopfzeilen keine @Media-Angabe (z.B. beim deutschsprachigen Teil des Frog-Story-Korpus). Bei anderen Korpora gibt es prinzipiell Audio- oder Videodateien, aber manche sind aufgrund von technischen Problemen nicht (mehr) verfügbar. Dann findet man bei @Media den Hinweis, dass die entsprechende Mediendatei fehlt (s. „missing“ in Beispiel 3 aus dem Szagun-Korpus). Darüber hinaus ist zu beachten, dass bei vielen Korpora zwar digitale Audio- oder Videodateien vorliegen und im Transkript angegeben sind, aber durch Passwörter geschützt sind und nur für bestimmte Projekte verwendet werden können. - @Situation
Die Angaben zur Aufnahmesituation, die her gemacht werden, sind nützlich, wenn man nach Aufnahmen mit bestimmten Situation sucht oder das sprachliche Verhalten von Kindern in unterschiedlichen Situationen vergleichen will. Manche Situationsbeschreibungen geben auch einen kleinen Einblick in die Erfahrung der Menschen, die Aufnahmen in mühevoller und langwieriger Arbeit abhören und verschriftlichen mussten (vgl. z.B. Beispiel 1). - @Transcriber
Wenn mehrere Personen für die Transkription von Daten aus demselben Korpus zuständig waren, wird auch oft die Person angegeben, die das betreffende Transkript erstellt hat. Dies ist wichtig, um wissenschaftliche Prozesse transparent zu machen oder potentielle individuelle Unterschiede im Transkriptionsverfahren zu entdecken, die berücksichtigt oder ausgeglichen werden sollten. - @Types
Auf dieser Zeile findet man eine kurze Charakterisierung der betreffenden Studie. So handelt es sich beispielsweise beim Leo- und beim Szagun-Korpus um Längsschnittstudien, bei denen die einzelnen Kinder über einen längeren Zeitraum hinweg immer wieder aufgenommen wurden („long“). Das Frog-Story-Korpus ist hingegen eine Querschnittstudie, bei der es jeweils nur eine Aufnahme für eine größere Gruppe von Personen gibt („cross“). Außerdem lag sowohl bei der Leo-Studie als auch bei der Szagun-Studie der Schwerpunkt auf freiem Spiel mit unterschiedlichem Spielzeug („toyplay“). Beim Frog-Story-Projekt ging es dagegen darum, Daten aus Erzählungen zu erheben („narrative“). Da beim Szagun-Korpus Kinder mit Cochlea-Implantat mit Kindern verglichen wurden, deren Sprach- und Hörentwicklung unauffällig verlief, wurde hier zusätzlich zwischen der Cochlea-Implantat-Gruppe (CI) und den Kindern mit typischer Entwicklung (TD für „typical development“) unterschieden.
Die Kopfzeilen präsentieren somit in stark verkürzter und systematischer Form viele Informationen. Das @-Symbol stellt dabei sicher, dass man die Zeichenketten auf der betreffenden Zeile vom Analyseprogramm wie CLAN (s. Blogbeitrag 4) ausschließen kann, wenn man beispielsweise Wort- oder Beispiellisten für Transkripte erstellt oder die durchschnittliche Anzahl von Wörtern in Kinderäußerungen berechnet. Außerdem kann die in den Kopfzeilen gespeicherte Information durch Markierungen wie „@ID“ oder „@Situation“ leicht gefunden werden. So kann man z.B. selbst in großen Datenmengen durch geeignete Suchbefehle mit „@Situation: Playoom at University“ all diejenigen Transkripte identifizieren kann, die in einem Spielzimmer in einer Universität aufgenommen wurden.
Hauptzeilen (Main Tiers)
Auf den unabhängigen Zeilen stehen die einzelnen transkribierten Äußerungen sowie ein Kode für die jeweilige Person, die diese Äußerung gemacht hat. Welche Person sich hinter dem Kode verbirgt, wird in den Kopfzeilen festgelegt, s. die Zeilen mit „@ID“ in den Beispielen 1-4. Dabei wird für jede neue Äußerung eine neue Hauptzeile angefangen, die mit dem Personenkode beginnt. Dieser besteht aus drei Großbuchstaben und steht zwischen einem Sternchen („*“) und einem Tabstopp.
Nicht jedes Sternchen steht allerdings am Anfang einer Hauptzeile. Sternchen werden auch verwendet, um Abweichungen von der Zielsprache – insbesondere nicht-zielsprachliche Wortformen – zu markieren (s. die Diskussion zu Annotationen auf der Hauptzeile). Dies sieht man im folgenden Beispiel.
Beispiel 5: : Hauptzeilen mit Markierung nicht-zielsprachlicher Formen aus der Transkriptdatei 020424.cha im Leo-Korpus
*CHI: gekaufen [: gekauft] [*] .
*MEC: hm .
*CHI: gekaufen [: gekauft] [*] .
*MEC: wer hat die gekauft ?
Rechtschreibung
Bei der Transkription der Äußerungen auf den Hauptzeilen wird in vielen CHILDES-Korpora durchgängig Kleinschreibung verwendet, außer bei Eigennamen oder beim Englischen I (ich). Dies gilt auch für die Kinder mit Cochlea-Implantat im Szagun-Korpus. Für das Leo-Korpus, für die Daten der Kontrollgruppe im Szagun-Korpus sowie im deutschsprachigen Teil des Frog-Story-Korpus folgt man hingegen den standarddeutschen Regeln der Groß- und Kleinschreibung.
Im Leo-Korpus und im Szagun-Korpus werden Umlaute verwendet, im deutschsprachigen Teil des Frog-Story-Korpus werden hingegen bei Umlauten einfach die Pünktchen über den Vokalen weggelassen (z.B. a statt ä). Dies ist bei Suchen im Text zu berücksichtigen. Außerdem ist zu beachten, dass man so nicht feststellen kann, ob ein Kind tatsächlich hüpft oder hupft gesagt hat. Für Analysen zum Wort(form)erwerb eignet sich ein solcher Datensatz somit nicht. Den Aufbau und Detailreichtum von Erzählungen kann man aber trotzdem analysieren.
Im CHAT-Format kann man das Symbol „_“, d.h. den Unterstrich, verwenden, um zusammengesetzte Wörter oder Phrasen zu markieren (zu beachten: In der Beschreibung des Leo-Korpus auf der Webseite steht hier noch „+“. Dies wurde aber mittlerweile in den Transkripten geändert). So werden im Leo-Korpus z.B. gängige Komposita wie Apfelbaum, Apfelringe oder Apfelsaftschorle zusammengeschrieben. Einige nicht-gängige zusammengesetzte Wörter, komplexe Namen, feststehende Ausdrücke, Akronyme oder Liedteile werden hingegen mit dem Unterstrich geschrieben (z.B. Mama_Ente, Mini_Kartoffeln, Rasender_Roland, lieber_Gott oder Tante_Trudl). Dies gilt es bei Suchabfragen zu beachten. Oft empfiehlt es sich, Suchen mit und ohne Unterstrich zu verwenden, da selbst identische oder sehr ähnliche Verbindungen im selben Korps uneinheitlich behandelt werden können. So findet man z.B. im Leo-Korpus sowohl LKW und L_K_W und sowohl ICE als auch I_C_E.
@-Markierungen für spezielle Typen von Wörtern
Spezielle Typen von Wörtern werden im CHAT-Format mit „@“ markiert, so dass man sie leicht erkennen und ggf. von Wortzählungen oder anderen Analysen ausschließen kann. In den hier diskutierten Korpora findet man u.a.:
- @o
Lautmalereien (Onomatopoeia) wie biep@o, aber auch Ausrufe wie huch@o oder Hilfe@o und Formen, die man weder dem Vokabular des Kindes noch dem Vokabular der beteiligten Personen zuordnen konnte (zu beachten: In manchen CHILDES-Korpora wird @i für Interjektionen verwendet.), - @c
spezielle (Kurz-)Formen des Kindes, z.B. Doppel@c für Doppeldeckerbusse - @n
spontane Neuschöpfungen (Neologismen), z.B. in der Äußerung Schnilfe@n Milfe@n Kilfe@n, die Leos Mutter in Aufnahme 041105 benutzt, - @f:
auf die betreffende Familie oder Kleingruppe beschränkte Namen, Wörter oder Phrasen, z.B. Ützel@f im Leo-Korpus, - @d:
Dialektwörter wie z.B. Luelle@d für Speichel, - @t:
Testwörter, z.B. Kunstwörter wie Bral@t, Muhne@t oder glorpen@t, mit denen man untersucht, ob Kinder grammatischen Markierungen (z.B. für Plural oder Vergangenheit) an Wörter anhängen, die sie zuvor noch nie gehört haben (vgl. z.B. die auf dem Sprachspinatblog bereits vorgestellten Kunstwortstudien, durch die das Kunstwort wug bekannt geworden ist)
Für weitere @-Markierungen auf den Hauptzeilen s. S. 45 im CHAT-Manual.
Markierungen für Laute, die keine erkennbaren transkribierten Wärter sind
Auf der Hauptzeile findet man nicht nur Markierungen für spezielle Wörter, sondern auch Markierungen für Laute bzw. Lautketten, die keine erkennbaren transkribierten Wörter sind:
- &=
einfache Ereignisse, die nicht auf einer Kommentarzeile weiter erklärt werden müssen (z.B. &=lacht oder &=weint), - &
eine Lautkette, die weder ein zielsprachliches noch ein umgangssprachliches Wort noch ein spezielles Wort mit @-Markierung ist, z.B. eine abgebrochene Wortform wie &ha für haben, - xxx
unverständliche Teile einer Äußerung, - www
nicht-transkribierte (Teile von) Äußerungen, z.B. Gespräche von Erwachsenen untereinander, die nicht an das Kind gerichtet sind und auf die das Kind nicht reagiert.
Die Markierung nicht-zielsprachlicher Wortformen
Bei der Markierung von richt-zielsprachliche Wortformen kommt es darauf an, inwiefern diese Form von der Zielsprache abweicht:
- Wenn eine zielsprachliche Wortform dadurch zustande kommt, dass ein Teil oder mehrere Teil dieser Wortform ausgelassen werden, setzt man die ausgelassenen Teile in runde Klammern. Dabei können die entstehenden Wortformen in der Umgangssprache akzeptabel sein, z.B. verkürzte Formen von Artikeln oder Pronomina wie (ei)n und (e)s. Mit den runden Klammern werden aber auch Auslassungen markiert, die zu nicht- Formen führen, die nicht zielsprachlich werden, z.B. (ge)macht.
- Wenn die Abweichung nicht in einer einfachen Auslassung besteht, wird das Zielwort hinter dem tatsächlich produzierten Wort in eckigen Klammern und nach einem Doppelpunkt hinzugefügt, z.B. se [: sie], wa [: wir], ham [: haben] oder wer [: wir]. Man kann in solchen Fällen bei der Analyse mit dem CLAN-Tool entscheiden, ob man die tatsächlichen produzierten Formen vor der Klammer sucht bzw. zählt oder die Standardformen, die das CLAN in den Klammern findet.
- Wenn die verwendete Form keine umgangssprachliche Variante ist, sondern eine Form, die in auch in der Umgangssprache nicht akzeptabel ist, folgt der Form (und ggf. der Ersatzform die Markierung „[*]“, z.B. runtergekommt [: runtergekommen] [*]
- Kombinationen verschiedener Markierungen sind auch möglich, z.B. ge(sch)neidet [: geschnitten] [*].
Die Markierung unklarer oder erklärungsbedürftiger Wortformen oder Lautketten
- Wenn nicht klar erkennbar ist, was die betreffende Person sagen wollte, kann man mit „[?]“ angeben, was man am ehesten gehört zu haben glaubt.
- Nach einer erklärungsbedürftigen Form kann mit einem Gleichheitszeichen in eckigen Klammern eine Erklärung hinzugefügt werden. So zeigt z.B. die Markierung „[= ja]“ nach einem hm an, dass dieses hm als Zustimmung zu interpretieren ist.
- Man kann auch wahrscheinliche Erklärungen hinzufügen, z.B. bei Neologismen. So verwendet z.B. Leo das Wort „Redekopf“; und im Transkript erscheint redekopf@n [=? Quatschkopf].
- Es kann auch eine separate Erklärungszeile verwendet werden (s. Abschnitt über abhängige Zeilen)-
- Wenn mehr als ein Wort unklar oder erklärungsbedürftig ist, wird die gesamte entsprechende Lautkette in spitze Klammern gesetzt (z.B. <haben mal> [=? Mama] die rausgemach(t) [*]).
„Nicht-flüssige“ Äußerungen: Pausen, mehrfache Ansätze Wiederholung und Abbrüche
Im CHAT-Format lassen sich verschiedene Typen von „Unflüssigkeiten“ (disfluencies) unterscheiden:
- Pausen werden mit „(.)“ markiert. Dabei kann man optional auch zwei oder drei Punkte verwenden, wenn die Pause länger oder sehr lang ist.
- Das Ende einer unvollständigen Äußerung steht „+…“, Wenn die Äußerung von einer anderen Person weitergeführt wird, beginnt die entsprechende Äußerung mit „++“.
- Abbrüche durch andere werden mit „+/.“ am Ende der abgebrochenen Äußerung gekennzeichnet.
- Selbstabbrüche erhalten die Markierung „+//.“.
- Wiederholungen von Wörtern oder Wortketten werden mit „[/]“ markiert.
- Wenn jemand sich bei einer Wiederholungen von Wörtern oder Wortketten selbst korrigiert, werden zwei Schrägstriche verwendet („[//]“).
- Wenn jemand mehrfach ansetzen muss, um ein Wort oder eine Phrase zu produzieren, tritt die Markierung „[MA]“ auf.
- Überlappungen von zwei Äußerungen zeigt man mit „+<“ an.
Kombinationen von Markierungen und Markierungen für Gesamtäußerungen
Nicht alle Markierungen auf der Hauptzeile beziehen sich auf einzelne Wörter oder Phrasen. So werden beispielsweise im Leo-Korpus ganze Äußerungen mit „[- diary]“ gekennzeichnet, wenn sie nicht aus einer Audio- oder Videoaufnahme stammen, sondern aus dem Sprachtagebuch für das Kind.
Die folgenden Beispiele zeigen Kombinationen von verschiedenen Markierungen. Dabei können auch recht kurze Sätze schon eine komplexe Transkription aufweisen. Dies gilt nicht nur für Kinderäußerungen (vgl. z.B. die letzte Äußerung von Leos Vater in Beispiel 6).
Beispiel 6: Hauptzeilen mit Markierungen aus der Transkriptdatei 020313.cha im Leo-Korpus
*VAT: eine Ente haben mer [: wir] gebacken .
*VAT: was haben mer [: wir] denn noch gebacken ?
*CHI: xxx gebackt [: gebacken] [*] .
*CHI: ja .
*VAT: aha@o .
*VAT: und hat (da)s Spaß gemacht <in Gertruds &kin , äh@o [/] äh@o > [//] in
Gertruds , äh@o [/] äh@o Sandkasten , hm ?
Beispiel 7: Hauptzeilen mit Markierungen aus der Transkriptdatei 020321.cha im Leo-Korpus
*MUT: und jetzt ?
*CHI: nein , aussteigen .
*MUT: wieso aussteigen , die wollen doch nach Halle ?
*MUT: oh@o [x 3] .
*CHI: ja .
*CHI: Halle [% MA] laufen .
*MUT: die laufen nach Halle ?
*CHI: ja .
*CHI: hier [/] hier [/] hier ist Halle .
*MUT: was haben die jetzt gemacht , die sind +…
*CHI: ++ ausgesteiget [: ausgestiegen] [*] .
*MUT: ach@o , die sind ausgestiegen .
*CHI: in Möck(ern) +/.
*MUT: +< ausgesteiget [: ausgestiegen] [*] , aha@o .
Außerdem ist zu beachten, dass nicht alle Korpora alle Konventionen verwenden, sondern nur diejenigen, die für die geplanten oder voraussichtlichen Analysen relevant sein könnten.
Abhängige Zeilen (Dependent Tiers)
Die Hauptzeilen mit den transkribierten Äußerungen können ergänzt werden durch abhängige Zeilen mit weiteren Informationen zur betreffenden Äußerung. Um Suchen zu vereinfachen und die Vergleichbarkeit der Korpora zu gewährleisten, gibt es in CHILDES eine kleine Menge von Zeilentypen, die jeweils mit einer eigenen Markierung aus dem Prozentsymbol und drei Kleinbuchstaben beginnen. Für das Leo- und das Szagun-Korpus sind die folgenden Markierungen relevant:
- %com [comments]
Kommentare, die es erleichtern, die Äußerung zu intrpretieren (z.B. Angabe des Objektes, auf das das Kind gerade zeigt, wenn es das da sagt), - %exp [explanation]
zusätzliche Kontextinformationen und Erklärungen dazu, warum eine bestimmte Äußerung wohl gemacht wurde, - %mor [morphosyntactic coding]
grammatische Annotation, insbesondere Angabe zu Wortart (z.B. Hauptwort/Substantiv/Nomen, Artikel oder Präposition) und grammatischer Markierung (z.B. „den&m&sg&acc“ für die Akkusativ.Maskulin.Singular-Form den).
Im deutschsprachigen Frog-Story-Korpus findet man diese Zeilen nicht. Dafür werden Zeilen mit @G verwendet, um die Nummern der beschriebenen Bilder anzugeben.
Ein Beispiel für den Aufbau von CHAT-Dateien und die verwendeten Markierungen
Das folgende Beispiel zeigt den Anfang einer CHAT-Datei (041006.cha aus dem Leo-Korpus) mit den oben beschriebenen Kopfzeilen, Hauptzeilen und abhängigen Zeilen. Dabei kann man auch sehen, dass die semi-automatisch vorgenommene morphologische Kodierung in einigen CHILDS-Korpora zwar eine hohe Korrektheitsrate aufweisen, aber dennoch einzelne Fehler auftreten (z.B. die Kodierung von ein Schläfchen als Nominativ). Außerdem weicht die Mutter von der Zielsprache ab, ohne dass dies markiert wird (chaotischen-AKK statt chaotischem-DAT).
Beispiel 8
@Begin
@Languages: deu
@Participants: CHI Leo Target_Child , MUT Maren Mother , WIL Wilhelmine
Sister
@ID: deu|Leo|CHI|4;10.06|male|group|MC|Target_Child|education||
@ID: deu|Leo|MUT|30;00.00|female|group|MC|Mother|Abitur_Lehre||
@ID: deu|Leo|WIL|1;07.10|female|group|MC|Sister|education||
@Media: 041006, audio
@Date: 09-JAN-2002
@Comment: Beginn Tonband
@Situation: CHI und MUT sind die ersten vierzig Minuten allein im
Kinderzimmer und spielen mit Lego und Lego_Figuren , dann
wacht WIL auf und sie gucken an Buch mit Kinderspielen an
und singen und sprechen Kinderverse
@Types: long, toyplay, TD
*MUT: Geschrei und Zeter , Zeter , Mordio gibt .
%mor: n|Geschrei&n&sg conj|und n:prop|Zeter cm|cm n:prop|Zeter cm|cm
n:prop|Mordio v|geben-PRES&3s .
*MUT: so , heute ist Mittwoch , der +…
%mor: adv|so cm|cm adv|heute cop|sein&PRES&3s n|Mittwoch&m&sg cm|cm
pro|der +…
*MUT: was hab(e) ich gesagt , der wievielte , der neunte ?
%mor: pro|was v|haben-PRES&1s pro:per|ich ge#part|sagen-PASTP2 cm|cm
det|der adjm|wievielt-e cm|cm det|der adjm|neunt&num:ord-e ?
*MUT: heute is(t) Mittwoch , der neunte Januar zwei tausend zwei .
%mor: adv|heute cop|sein&PRES&3s n|Mittwoch&m&sg cm|cm det|der&m&sg&nom
adjm|neunt&num:ord-e n|Januar&m&sg&nom adj|zwei&num:card
adj|tausend&num:card adj|zwei&num:card .
*MUT: es ist doch schon wieder zwanzig vor drei .
%mor: pro:per|es cop|sein&PRES&3s adv|doch adv|schon adv|wieder
adj|zwanzig&num prep|vor adj|drei&num:card .
*MUT: wir sind in Leos chaotischen süßen Zimmer .
%mor: pro:per|wir cop|sein&PRES&13p prep|in n:prop|Leos
adjm|chaotisch&n&sg&nom&acc-en adjm|süß-en n|Zimmer&n&sg .
*MUT: Wilhelmine macht gerade hoffentlich noch ein Weilchen ein
Schläfchen .
%mor: n:prop|Wilhelmine v|machen-PRES&3s adv|gerade adv|hoffentlich
adv|noch adjm|ein&det&n&sg&nom n|Weilchen&n&sg&nom&acc
adjm|ein&det&n&sg&nom n|Schläfchen&n&sg&nom&acc .
CHILDES-Kindersprachdaten in CHILDES finden und anschauen
CHILDES-Daten finden
Wenn man sich CHILDES-Kindersprachen im Browser anschauen möchte, kann man auf der CHILDES-Webseite auf das Verzeichnis der Korpora („index to corpora“) clicken und dort ein Korpus auswählen.
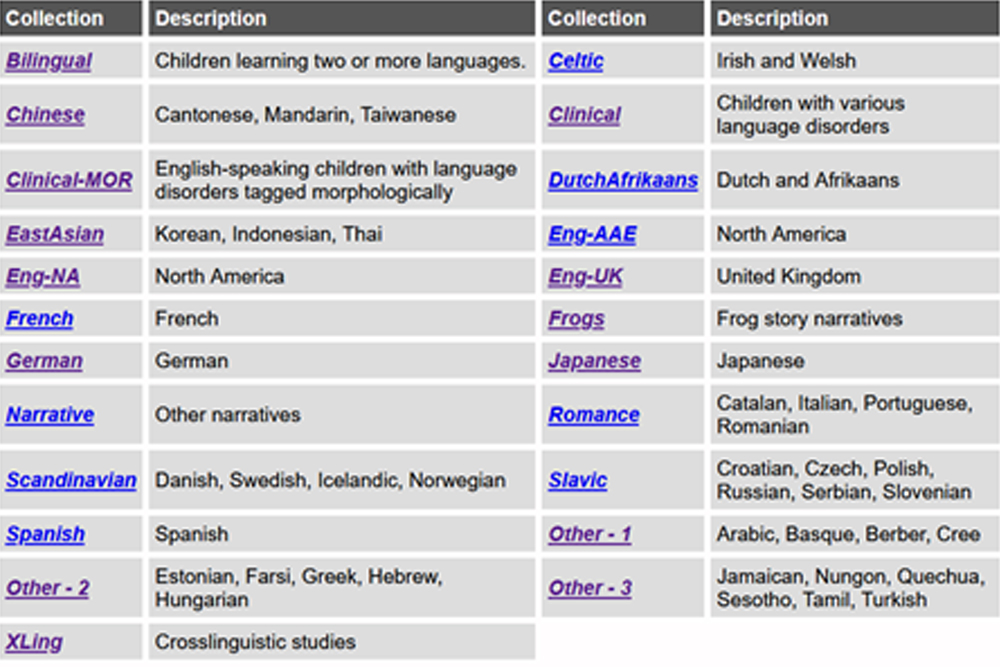
Korpus- und Sprachliste auf der CHILDES-Webseite
Dann gelangt man auf die jeweiligen Korpusseiten, z.B. auf die Seiten für das Leo-Korpus, das Frog-Story-Korpus und das Szagun-Korpus. Auf diesen Korpusseiten gibt es die Links zum Anschauen bzw. Herunterladen der Daten sowie Literaturangaben und weitere Informationen zum Korpus (z.B. Aufnahmehäufigkeiten oder Besonderheiten bei der Transkription oder bei Markierungen von Wörtern oder Äußerungen).

Info-Seite für das Frog-Story-Korpus
Die herunterladbaren Transkripte liegen im CHAT-Format vor. Die Transkripte auf der Webseite haben das xml-Format, damit sie dort direkt eingesehen und durchsucht werden können. Dabei werden im Text dieselben Markierungen und Annotationen für die beteiligten Personen, Fehler, Wortarten etc. gemacht wie bei den herunterladbaren Texten.
CHILDES-Daten im Browser anschauen
Wenn man auf einer Korpusseite auf „browsable transcripts“ klickt, gelangt man direkt zu den Tanskripten und – falls vorhanden – Audio- bzw. Videodaten.

Info-Seite für das Leo-Korpus
Wenn man auf der linken Seite Dateien anklickt, erscheinen im Fenster auf der rechten Seite die entsprechenden Transkripte und links unten kann man ggf. die Mediendateien abspielen. Dann kann man einfach mit der Suchfunktion des Browsers nach bestimmten Wörtern oder auch nach Markierungen für nicht-zielsprachliche Äußerungen o.ä. suchen. Links unten auf der Seite gibt es ein Fenster, in das man Befehle für das Analysetool CLAN eingeben kann. Diese Befehle werden in CHILDES-Tutorial 4 auf dem Sprachspinat-Blog erklärt.
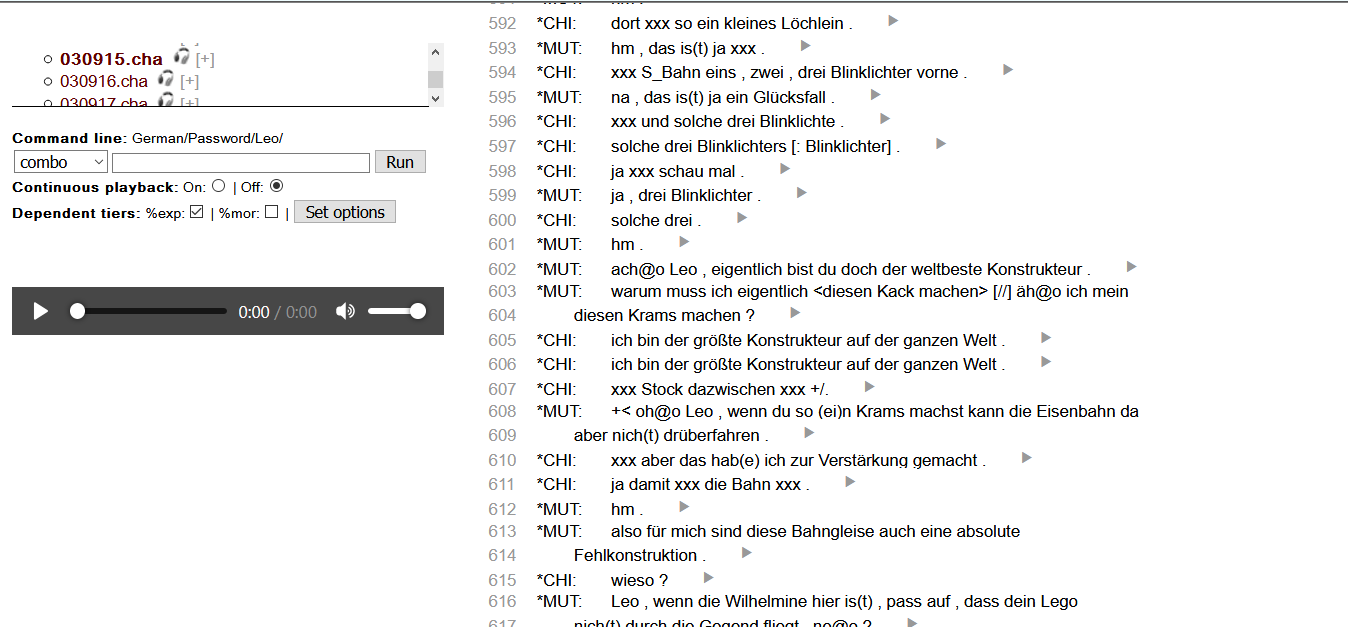
CHILDES Browser
CHILDES-Kindersprachdaten herunterladen und anschauen
Auf der Webseite für das jeweilige Korpus findet man auch Links zum Herunterladen von Transkripten („download transkripts“).

Info-Seite Szagun-KorpusKlickt man auf diese Links, startet der Download einer komprimierten (zip) Datei. Diese speichert man auf dem Rechner und kann sie dann mit einem Doppelklick öffnen. Danach kann man die Daten in ein Verzeichnis extrahieren, das nicht auf dem Desktop sein sollte, sondern unter „Dokumente“. Dieses Verzeichnis für die Korpusdaten sollte speziell für das betreffende Korpus angelegt werden. Daten von unterschiedlichen Korpora und Kindern können nämlich bei gleichem Aufnahmealter der Kinder denselben Namen tragen. Bei Speicherung im selben Verzeichnis könnte es zu so zu unbeabsichtigten Überschreibunge und Datenverlust kommen.
Das CHAT-Format erlaubt die Analyse von heruntergeladenen Transkripten mit den CLAN-Tools. Dazu muss man CLAN installieren und die Transkripte mit Hilfe dieses Programms öffnen. Wenn man das CLAN-Programm nicht installieren kann oder möchte, kann man Transkripte mit der Extension .cha nicht einfach durch Doppelklicken auf die Datei öffnen.
Die CHAT-Dateien sind aber reine Text-Dateien mit UTF-8-Format und lassen sich in allen gängigen Textverarbeitungsprogrammen (z.B. Word) öffnen. Damit man die Dateien weiter mit CLAN verarbeiten kann, sollten sie aber nicht mit einem Textverarbeitungsprogramm bearbeitet und dann in dessen Format gespeichert werden. Möchte man in einem Transkript interessante Stellen farblich markieren oder Kommentare eingeben, so sollte man das Transkript mit einem Textverarbeitungsprogramm öffnen, dort die Markierungen bzw. Kommentare hinzufügen und die so modifizierte Datei im Format des Textverarbeitungsprogramm speichern (z.B. im docx-Format von Word). Das ursprüngliche CHAT-Transkript verbleibt so im .cha-Format und kann weiterhin für CLAN-Analysen genutzt werden kann.
Übungen
Die Entwicklung von erzählerischen (narrativen) Fähigkeiten (Frog-Story-Korpus)
Laden Sie für jede Altersgruppe (3 Jahre, 5 Jahre, 9 Jahre und 20 Jahre) jeweils eine beliebige Datei aus dem deutschsprachigen Teil des Frog-Story-Korpus herunter. Beantworten Sie für jede Altersgruppe die folgenden Fragen und vergleichen Sie dann die Antworten für die vier Aufnahmen:
- Welche Details der Geschichte werden jeweils erwähnt und welche nicht?
- Wann erfolgt der Bezug auf Personen oder Tiere durch Pronomina wie er oder sie und wann werden komplexere Phrasen wie der Frosch verwendet?
- Welche sprachlichen Mittel werden eingesetzt, um zeitliche oder kausale Zusammenhänge anzeigen (z.B. dann oder weil)?
- Wie oft wird von solchen sprachlichen Mittel Gebrauch gemacht?
Welche Entwicklungen der lexikalischen, grammatischen und erzählerischen Fähigkeiten lassen sich bei diesem Vergleich beobachten?
Auswirkungen von Hörstörungen (Szagun-Korpus)
Wählen Sie eine beliebige Aufnahme eines Kindes mit Cochlea-Implantat im Szagun-Korpus aus und vergleichen Sie diese Aufnahme mit der entsprechenden Aufnahme des gleichaltrigen Kindes aus der Kontrollgruppe in Bezug auf
- Wortschatz,
- Satzstruktur (Verwendung von Nebensätzen, zielsprachliche Wortstellung, Satzlänge) und
- Wortformen und grammatische Markierungen (z.B. Kontraste zwischen Einzahl/Singular und Mehrzahl/Plural wie bei Zug-Züge oder Gegenwart/Präsens vs. Vergangenheit/Präteritum wie bei laufe-lief).
Wortformen (Leo-Korpus)
Finden Sie die Datei 030915 im Leo-Korpus und suchen Sie das Wort Blinklicht im Transkript. Auf der Webseite können Sie dies mit der Suchfunktion ihres Browsers tun (in Windows z.B. mit Ctrl+F, Eingabe des Wortes und Bestätigung der Eingabe durch Enter/Return). Sie können die Datei aber auch herunterladen und die Suchfunktion Ihres Textverarbeitungsprogramms verwenden. Beantworten Sie die folgenden Fragen:
- Welche Formen von Blinklicht(er) verwendet Leo?
- Wie passen diese Befunde zu Ergebnissen aus der bisherigen Forschung zum Pluralerwerb (s. die Sprachspinat-Literaturliste zum Spracherwerb, insbesondere aber Kauschke 2012, Kapitel 6.2 für einen Überblick)?
- Wie reagiert die Mutter auf Leos Versuche der Pluralbildung?
- Wie reagiert die Mutter auf andere Verwendungen des Wortes Blinklicht?
Elterliche Reaktionen auf lautliche Abweichungen von der Zielsprache (Szagun)
Laden sie die Datei 021017 von Sino aus dem Szagun-Korpus (Kontrollgruppe) herunter oder schauen Sie sich diese Datei auf der CHILDES-Webseite an. Das Kind in dieser Aufnahme hat Probleme mit der Aussprache des Wortes trinken. Hier sind zwei Beispiele dafür.
- Beispiel A:
*MOT: du kannst was trinken.
*CHI: ja.
*CHI: was (t)rinken.
%com: imitiert.
*MOT: hast du was zu trinken für mich?
*CHI: ja.
- Beispiel B:
*CHI: ja.
*CHI: jetz(t) dib [: gib] nochmal (T)rinken.
*MOT: jetz(t) gibt (e)s nochmal Trinken?
*CHI: ja.
*MOT: hier sind so dunkle Flaschen.
- Finden Sie weitere Belege für die Verwendung des Tätigkeitsworts/Verbs (t)rinken im Transkript für diese Aufnahme. Denken Sie an mögliche existierende Formen wie trinkst, trank oder getrunken, und mögliche nicht zielsprachliche Formen wie ge(t)rinkt.
- Beschreiben Sie, wie das Kind bei den o.a. Beispielen und bei den anderen Belegen für trinken im Transkript von der Zielsprache abweicht.
- Vergleichen Sie diese Abweichung von der Zielsprache Tabelle mit lautlichen Abweichungen von der Zielsprache, die in der Spracherwerbsliteratur beschrieben wurden (s. z.B. Kapitel 4.2.2 der Spracherwerbseinführung von Kauschke 2012). Welcher phonologische Prozess liegt den Abweichungen von der Zielsprache in den Beispielen A und B zugrunde?
- Produziert Sino auch bei anderen Wörtern Abweichungen von der Zielsprache, die auf demselben phonologischen Prozess beruhen wie die Reduktion von trinken auf rinken? Sie können hierzu u.a. nach runden Klammern suchen, die Auslassungen markieren.
- Beschreiben sie, wie die Erwachsenen (Versuchsleiterin Steffi und die Mutter) auf die Abweichung von der Zielsprache reagieren.
Höflichkeit und soziale Kompetenzen
Finden Sie die Datei 030003.cha von Anna aus der Kontrollguppe des Szagun-Korpus in der CHILDES-Datenbank. Schauen Sie diese Datei entweder im Browser an oder laden Sie sie herunter und öffnen Sie sie in ihrem Textverarbeitungsprogramm. Verwenden Sie die Suchfunktion des Browsers (bei Suche auf der Webseite) oder die Suchfunktion ihres Textverarbeitungsprogrammes (bei Herunterladen des Transkripts) dazu, um im Transkript nach Höflichkeitsformeln wie danke, bitte oder Entschuldigung zu suchen. Beantworten Sie die folgenden Fragen:
- Wann und wie verwenden Mutter und Kind solche Formeln?
- Wie versucht die Mutter, das Kind dazu zu bewegen, solche Formeln zu verwenden?
Mein persönlicher Sprachspinat-Tipp
Wer Kindersprachdaten anschauen möchte, findet auf der Sprachspinat-Leseliste. Ideen und Inspiration für die Betrachtung oder Analyse von Daten. Eine weitere Inspirationsquelle sind Videos zum Spracherwerb sowie Webseiten von Forschungsinstituten, Projekten oder Sprachförderungs- und Sprachbildungsorganisationen. Weitere Informationen zum Spracherwerb werden regelmäßig mit dem Tag „Spracherwerb“ auf dem Sprachspinat-Blog gepostet.
Pingback: Kindersprachdaten aus der CHILDES-Datenbank anschauen und analysieren. Teil 1: Eine Einführung in die CHILDES-Datenbank für Kindersprachdaten und drei Sammlungen deutscher Kindersprachdaten (Leo-, Frog-Story- und Szagun-Korpus) | Sprache Spiel Natur
Pingback: Kindersprachdaten aus der CHILDES-Datenbank anschauen und analysieren. Teil 1: Eine Einführung in die CHILDES-Datenbank für Kindersprachdaten und drei Sammlungen deutscher Kindersprachdaten (Leo-, Frog-Story- und Szagun-Korpus) | Sprache Spiel Natur